The pipeline I work on has only ever generated code against TypeScript. No Python target has been decomposed, no Go target rendered, and no non-TypeScript project has ever gone through it from ticket to committed code. And yet one of the load-bearing rules on every commit is a question about a language no target project has ever driven through it: would this still be correct if the target were Python, or Go? On its face that is the definition of over-engineering, building for a case that does not exist. The reason it is not over-engineering is a specific incident, where the discipline caught a bug that had not happened yet and could not happen until a second language arrived, and made the fix cheap by catching it while there was still only one consumer.
This is a post about polyglot discipline in an agent pipeline: not the architecture diagram, which is the easy part, but the habit that keeps language-specific assumptions from leaking into language-agnostic code, and why that habit is worth paying for before you have a second language to justify it.
The bug that had not happened yet
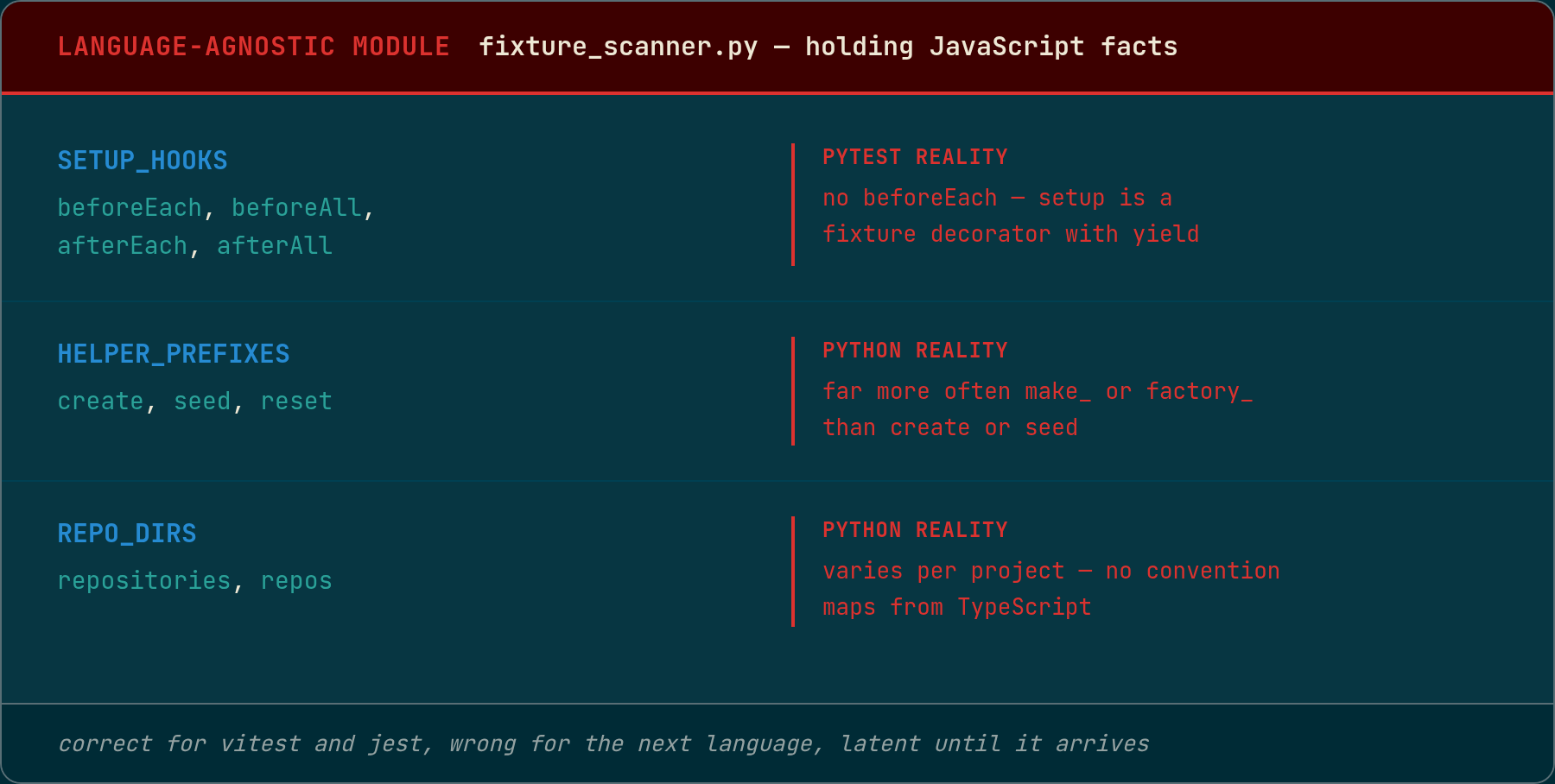
The pipeline discovers a project’s test fixtures by scanning its test files: which setup hooks run, which helper functions seed data, where the repository helpers live. That scanner was shared code, meant to be language-agnostic, because every language has fixtures and the rest of the pipeline should not care which language produced the catalog.
It was carrying three constants at module scope. The set of setup-hook names it looked for was beforeEach, beforeAll, afterEach, afterAll. The prefixes it recognised for data helpers were create, seed, and reset. The directory names it treated as repositories were repositories and repos. Every one of those values is correct, and every one of them is correct only for JavaScript with vitest or jest. Python’s pytest does not have beforeEach; its notion of setup is a fixture decorator with a yield. Python data helpers are far more often make_ or factory_ than create or seed. The directory conventions are whatever a given project chose. The constants were not wrong. They were JavaScript facts living in a module that claimed to be language-neutral, and the day a Python project arrived they would all be silently, confidently wrong.
Nothing was broken, and that was the danger. Every test passed, because every test was JavaScript, and the constants are right for JavaScript. The bug was latent, scheduled to fire on the first pytest project and not one moment sooner. It surfaced during a review of an unrelated change, when the polyglot rule got asked out loud, would this hold for the second language, and the answer was plainly no. The constants got filed as a known liability, with a note on exactly how each one breaks for pytest, mocha, and Go’s testing package, before any of those languages existed in the system to break on them.
Why catching it early was the whole point
The refactor itself is the same whether you do it now or in six months: move those constants out of the shared module and into a per-framework scanner, so the JavaScript scanner knows JavaScript conventions and a future pytest scanner knows pytest’s. The cost of the change does not depend on when you make it. What depends on when you make it is everything around the change.
Do it now, with one consumer, and it is a calm refactor with nothing depending on the old shape. Do it after a pytest scanner has landed, and you are changing a contract that a second consumer now relies on, under the pressure of a Python project that is failing in a way that looks like a fixture-detection bug rather than an architecture problem. At that point the three bad options are to ship wrong defaults and hope, to duplicate the lookup logic per language and accept the drift, or to fork the catalog and maintain two of them. None of those is the clean refactor that was available for free while there was still only one language.
The discipline does not make the change cheaper. It moves the change to the moment when it is cheapest, which is before the second consumer exists.
That is the move that was actually made here, while JavaScript was still the only consumer. The framework-specific scanning was split out of the shared catalog into its own framework-named module, so the catalog went back to holding only the language-neutral data model and the dispatcher that routes to a scanner, the JavaScript conventions now live in the JavaScript scanner, and the next language gets a sibling scanner to write rather than a shared contract to renegotiate. Catching is not the same as fixing, and the value of catching early is that you can then fix early, for free.
This runs through the whole project. The junior instinct is to hardcode for the case in front of you and generalise when needed, and the trap in that instinct is that “when needed” is precisely the moment you have the least room to generalise cleanly, because something is already depending on the assumption you baked in.
The architecture that makes a language a driver, not a rewrite
The reason “would this hold for the second language?” is answerable at all is that the pipeline is built so that adding a language is supposed to be writing a driver, not editing the core. The core is language-neutral by construction. The registry describes the code in terms no language owns. The stages that decompose a ticket, synthesize its facts, and render its tests read from the registry and emit operations; none of them contains a branch on the language. Everything that is language-specific lives behind a dispatch, and there are several of them.
Parsing routes by file suffix to a per-language walker, with Tree-Sitter handling the grammars it supports and a secondary fallback for the extensions it does not. Module classification dispatches by suffix to a per-language classifier. The type-aware extraction runs through a per-language driver backed by that language’s language server. The fixture scan runs through a per-framework scanner. And the language-level vocabulary, the words and conventions a prompt would otherwise hardcode, comes from a per-language configuration rather than being baked into the prompts, so that nothing in them assumes a TypeScript idiom. Each of those is a seam. The promise of a seam is that a new language is a new implementation behind it, and the core never learns the new language exists.
The fixture constants were a violation of that promise. They were language-specific facts that had escaped their seam and settled into shared code, and the discipline is what noticed the escape.

The same discipline, applied to prompts
A seam can leak into the model’s instructions just as easily as into code, and the same habit catches it. One prompt described how to name a database table: tables are PascalCase singular, derived from the project’s create<Table> and seed<Table> helpers, not the lowercase plural of the raw database layer. That reads as universal guidance if the only codebase you have ever seen is this one. It is TypeScript guidance. A Python project with snake_case tables and make_table helpers would have the model confidently producing the wrong names from instructions that sounded language-neutral.
A better example was not the answer, because any example is a convention in disguise. It was to delete the convention from the prompt and point the model at the fixture catalog as the single source of truth: match these strings exactly, case and pluralization included, because every project and every language uses its own convention and you should not apply intuitions from the storage layer.
A prompt that teaches a convention is a hardcoded language assumption with extra steps.
A prompt that points at the machine-extracted catalog and says “copy this exactly” carries no language in it at all. De-hardcoding the instruction is the same move as de-hardcoding the code: replace the baked-in convention with a lookup against a fact.
The limit: a seam is a hypothesis until you drive a second language through it
The architecture diagram does not show this. The pipeline has never taken a non-TypeScript project from ticket to committed code, and most of the machinery above the parser is unproven on anything but TypeScript. The picture is layered, and being exact about which layers are real is the whole credibility of the claim.
The one layer that genuinely spans languages is parsing, and for Python it spans more than a test fixture. The Tree-Sitter walkers for Python, Go, and CSS are real implementations, not stubs, exercised in the test suite against sample and deliberately malformed files in each language. Python goes further than that. Because the pipeline is written in Python, its own large codebase is parsed and indexed by the same tooling, so the symbol layer has been exercised against a substantial real Python project, the pipeline’s own, just never an external one. That lowest seam, suffix to walker, is not a hypothesis.
Above it, the picture is TypeScript-only in the way that counts. TypeScript is the only language the full toolchain has been run on against a real external project, with a real dependency tree behind it. A Python language server is part of that toolchain and is used against Python internally, on the pipeline’s own code, but it has never been pointed at an external Python project the way the TypeScript path has at a real TypeScript one, least of all one with a large dependency count. The higher seams tell the same story: module classification, route handling, and fixture scanning are built out for TypeScript and only partly, or not at all, for Python and Go. No external project in any language but TypeScript has ever been synced, decomposed, and rendered end to end.
If a second language is coming, it is Python, and not by accident. The pipeline has been parsing its own Python since the day it was written, and the Python language server already runs against Python internally, so much of the groundwork is already there. A first external Python project would be an extension of that rather than a from-scratch build, where Go would start a step further back, from a couple of test fixtures and no real project at all.
So the claim has to be stated precisely. The pipeline is polyglot by construction, meaning the core carries no language and the language-specific work is isolated behind dispatch points. Whether the construction holds above that lowest seam is unproven, because the only real test of the higher seams is a second language flowing all the way through them, and that has not happened.
A seam you have designed but never driven a second language through is a hypothesis, not a fact.
It is entirely possible that the first real pytest project reveals an assumption that escaped into the core in a way no review caught, and the honest expectation is that it will reveal at least one. The discipline lowers the odds and shrinks the blast radius; it does not get to claim the result before the experiment.
Even while it waits for that experiment, the discipline is not dormant, and the reason is structural. The pipeline is written in Python and runs its analysis over its own code, so it reads Python every day, while everything it generates is TypeScript. The language I build it in and the language it builds are already different, which makes working on it a two-language job by default: the core has to stay language-neutral just for me to dogfood it on its own Python and still ship TypeScript. It is a kind of two-for-one. A language assumption that leaks into the core tends to surface in my own daily use, against Python, long before it would reach an external Python target.
That is why the rule is a question and not a guarantee. “Would this hold for the second language?” is something you ask because you cannot answer it by running the tests, since the tests are all one language. You answer it by reading the change and deciding whether it assumes a convention or reads one. Every hardcoded setup-hook name, every PascalCase example in a prompt, every branch that quietly expects camelCase, is an assumption that the second language will turn into a bug. Finding them by habit, while there is still only one language and one consumer, is the cheapest the search will ever be. This is one codebase, one language proven, still R&D, and the second language is the real exam. The work between now and then is making sure that when it arrives, it is a driver to write and not a core to untangle.