What this post is
This post is a follow-up to Per-Field Hallucination Fixes Hit a Ceiling: 248 Runs on an AI Coding Agent, published 2026-04-17. That post was empirical. It measured 248 ticket runs against a Bernoulli prediction of LLM hallucination rates and identified a ceiling that per-field accuracy work alone could not break.
This one is the architectural follow-up. It describes what shipped since to attack that ceiling and why, with one worked case study from a recent run. It does not claim the headline 21 percent number from the original has improved.
The empirical re-run, when it happens, will be its own post. The headline measurement deserves its own measurement. Conflating “we built X” with “and therefore Y percent improvement” would be the marketing-deck shape, not the engineering one.
TL;DR
The original 248-run post modelled LLM hallucination in an agent pipeline as a Bernoulli trial. Each field the Planner emits is a weighted die roll, joint probability decays multiplicatively, and at twenty fields with 0.95 per-field accuracy the predicted first-pass success rate is 36 percent. The measured rate was 21 percent. The post argued the gap was both lower per-field accuracy and non-independence between fields, and that per-field fixes would hit a ceiling because some failures aren’t on the dice-roll curve at all.
Three weeks of architectural work later, the central change isn’t that per-field accuracy got better. The pipeline stopped depending on the dice rolls going well in the first place. Where a decision is computable from machine-extracted facts, the LLM is removed from that decision entirely. Where the LLM must remain creative, on intent, naming, scenario authoring, its output is validated and rewritten structurally rather than trusted. Where bad LLM output survives every upstream check, an end-of-ticket Reviewer catches it as a hard structural rejection. The week this post was drafted, that backstop did exactly that. It rejected code that passed type-check, tests, and language-server diagnostics but would have failed the project’s lint CI. The previous pipeline would have shipped that bug.
To repeat for emphasis: this post does not claim the headline 21 percent number has improved. It claims the architecture has fewer places where it depends on a lucky roll. Whether that translates into a higher first-pass success rate is the empirical question a later post will measure.
Recap: the four-bucket failure breakdown and the per-field ceiling
The 248-run post split outcomes into four buckets. 21 percent first-pass complete. 3 percent recovered after the Debugger re-planned. 27 percent reached the Debugger and failed anyway. 49 percent stalled before the Coder stage. Of the 67 Debugger-diagnosed failures, about two-thirds were field-level hallucinations, the kind where the Planner emitted a wrong filepath or signature, the Coder followed it into a wall, and the post-mortem named a specific field as the culprit. That class of failure is what the Data Path Principle was designed to eliminate, and the post made the case that machine extraction had been working on those.
The other third was the ceiling. Some failures were instruction ambiguity, the Coder interpreting “implement this new function” as “replace the file with this new function.” Others were structurally unsatisfiable criteria, tests that no field-value combination could ever satisfy because the test itself was incompatible with the source topology. Better field accuracy could not move either category.
The post named what was on paper for the next iteration. A split-surface manifest where the Planner only authored decisions and a Synthesizer populated facts. A feasibility gate that resolved each acceptance criterion before any builder fired. The closing line: “Whether it holds up on the next 248 runs is the measurement worth the follow-up post.”
What the post didn’t quite name explicitly, but what became the operating principle since, is the deeper thesis. Field-level hallucination is itself a special case of LLM non-determinism. The architectural answer is to engineer around the dice rolls rather than try to make them more accurate.
Three layers of engineering around LLM non-determinism
Each architectural change since the original post falls into one of three layers, ordered by how aggressively each engineers around the LLM.
Layer 1 removes the LLM from the decision entirely. When a decision is mechanically computable from machine-extracted facts, the pipeline computes and applies it. No LLM call. No dice roll. This is the original Data Path Principle, applied broadly.
Layer 2 lets the LLM author, then validates and transforms. When the decision genuinely requires creative authoring, like prose, scenario descriptions, or naming, the LLM produces output and the pipeline validates it against structural facts. If the validation fails, the pipeline doesn’t warn-and-pass. It rewrites or drops the bad output before any downstream stage sees it.
Layer 3 catches what slips through with structural backstops. Even with Layers 1 and 2, the LLM still authors something somewhere. The end-of-ticket Reviewer reads the cumulative diff and rejects it on structural correctness criteria the LLM never had to think about, including issues no upstream gate could have caught.
Each section below is one or more concrete shipped pieces, mapped to which layer it belongs to.

Layer 1: decisions removed from the LLM
The Synthesizer and the split-surface manifest retired the in-pipeline Planner LLM stage entirely. The Brain layer, the stage that decides what to build, became an authoring-time concern rather than a runtime one. The runtime pipeline reads structured tickets directly and runs deterministic synthesis. Every fact field that the Planner used to emit, like file paths, function signatures, dependency resolutions, mock targets, sub-ticket scope, immutable regions, is now populated from registry queries, call-graph traversal, and source extraction. The Planner writes decisions. The Synthesizer populates facts. Each fact field that moved is one die that’s no longer rolled per ticket.
The pipeline reads these structured tickets directly, but it doesn’t author them. A separate ticket-generation stage takes operator prose and produces the typed ticket the runtime pipeline consumes. That stage is its own substantial architectural surface, with multiple LLM substages, validators, and deterministic transformations of its own. The operator-facing side of that stage (a grounding chat that captures design decisions interactively before the pipeline runs) has since been covered in depth.
The feasibility gate runs inline inside the Synthesizer. It resolves each acceptance criterion against the registry, the language server, and Tree-Sitter at manifest-validate time, before any builder fires. Unsatisfiable criteria get rejected with a structured alternative, not silently passed downstream. The original post’s “structurally unsatisfiable criteria” failure class, where the dice roll was irrelevant because no field value could satisfy the test, is now caught before any dice are rolled.
The chain-selection components closed a non-determinism surface the original post didn’t name: chain-decomposition variance. Even with structural facts, the LLM’s choice of which chain to thread through was a non-deterministic decision. Three consecutive runs of the same prose against the same code produced two different intents and two different decompositions. The fix made the chain selection a deterministic ranking over machine-extracted symbols, with an explicit threshold that surfaces a clarification request when no clear winner exists. The same prose against the same code now produces the same decomposition on every run.
Op-driven sub-tickets removed the Coder LLM from threading work. An operation (or “op”) is a typed code transformation with a structured input and a deterministic source edit as output, executed by the pipeline without an LLM call. Adding a parameter to a function and forwarding it through a chain of callers, the kind of mechanical transformation a Coder used to produce, is now an op. Each op is executed by Tree-Sitter and language-server traversal. On a recent chain ticket from the ~100k line TypeScript monorepo, the new pipeline lands six of eight sub-tickets via op handlers. Those six used to be six Coder cycles, each with all the dice-roll variance that implies.
Layer 2: the LLM authors, the pipeline validates and transforms
A recent chain-ticket run failed two tests because the LLM authored an assertion against a mock that couldn’t intercept the actual call path. The mock target was a module-export spy whose only caller lived in the same source module, and module-export spies don’t intercept intra-module calls. The fix went through three rounds before landing in the right shape.
The first ship was a stderr warning when the validator detected the bad assertion. The second extended the LLM’s context with reachability information for each mock target. Both were band-aids. The LLM still got to decide whether to follow the rule. The third ship was a transformer that rewrites the bad LLM output deterministically before any downstream stage sees it. The LLM still rolls its dice. The pipeline just stops trusting the outcome.
The LLM still rolls its dice. The pipeline just stops trusting the outcome.
The same shape applies to mock-import-path mismatch detection. The LLM authors a vi.mock(...) declaration. The pipeline checks against the actual import paths used by consumers in the scenario’s reachable file set. If the mock target doesn’t match, the assertion gets dropped and a structured note is emitted to the operator’s run log. The LLM doesn’t get to decide whether the mock will work at runtime. The pipeline computes that deterministically from the import graph.
This is the Data Path Principle Corollary, made operational. Machine-extracting a fact and showing it to the LLM is necessary but not sufficient. If the LLM is asked to compose those facts into a derived decision, like reachability, observability, or schema-validity, the composition is still a hallucination surface, just one layer above the raw facts. The pipeline either constrains the choice or rewrites the output.
Layer 3: end-of-ticket structural backstops
A language-server autofix pass runs after each Coder write attempt and before the test gate. Quickfixes for missing imports, organize-imports for dedup and sort, and the formatter pass all run before the Coder’s output reaches the type-check gate. Coder cycles aren’t burned on what the language server can fix in milliseconds.
A language-server type-check runs end-of-ticket on the cumulative diff. It catches cross-sub-ticket interactions per-sub-ticket gates couldn’t see. A sub-ticket whose own files compile but breaks an importer no individual sub-ticket touched. Failure raises a typed exception with full diagnostic context. The architecturally correct destination for that exception is the Debugger, which already routes per-stage failures to the right repair stage. Extending that routing to consume end-of-ticket typed exceptions (Planner re-decomposition for manifest issues, Coder repair for code issues, test-author re-run for oracle issues) was the architectural piece still in flux at the time this post was written. Four of the six end-of-ticket gates now route through the Debugger router to a fail-safe Coder repair pass rather than terminating; see The Debugger Becomes a Router for the current shape, including why the named destinations here differ from what shipped.
The end-of-ticket Reviewer replaces what used to be a per-sub-ticket Reviewer call. The previous shape had two failure modes. The per-sub-ticket Reviewer couldn’t see cross-sub-ticket interactions, because each call was scoped to one sub-ticket’s diff. And it was skipped entirely for op-driven sub-tickets, leaving the deterministic-decomposer chain with zero Reviewer coverage. The new shape runs Reviewer once at the ticket boundary on the full cumulative diff, regardless of which sub-tickets came from LLM Coder versus deterministic ops. Failure raises a typed exception with the same operator-actionable shape as the language-server failure, routing through the same Debugger pathway, which has since landed.

Stepping back: a domain-specific language for ticketed engineering
The original 248-run post named three properties of the Lego Instructions Principle as the goal. Every piece is in the box. The instructions are unambiguous. Impossible assemblies don’t appear. Three weeks later, those three properties map onto concrete shipped surfaces, not as aspirations but as structural enforcement.
Every piece in the box maps to the Synthesizer. Every fact field is populated from registry queries before any builder runs, so the Coder never hunts. Op handlers go further: the op’s target is a registry-resolvable symbol and its traversal is deterministic, so the Coder never fires at all.
Unambiguous instructions maps to the structured ticket format. Acceptance criteria are typed structures (subject, predicate, object), not prose. Operations are typed envelopes, not “implement this thing.” Tests are framework-agnostic structured plans, not free-form code. The component that converts a structured test plan into runnable test code produces deterministic output. The builder never picks between two plausible interpretations because there aren’t two. The structured authoring already collapsed the ambiguity at the schema layer.
No impossible assemblies maps to the feasibility gate plus the Layer 2 transformer layer. The feasibility gate rejects unsatisfiable criteria before any builder runs. The transformer layer catches the second-order case, where an LLM-authored mock setup is structurally valid but unsatisfiable. The pipeline rewrites or drops the mock declaration before the test runs.
What I ended up with, structurally, is a domain-specific language (DSL): a structured input format with a constrained vocabulary, typed schemas, and defined execution semantics, designed for one purpose. The LLM authors in the DSL, and the pipeline executes the DSL deterministically. The Lego framing in the original post was a metaphor. The DSL is what makes the metaphor executable.
The framing also clarifies what’s still LLM-authored versus what isn’t. The LLM authors ticket text, structured acceptance criteria, scenario descriptions, case names, mock setup intent, and the choice of which target to assert against. The LLM does not author file paths, function signatures, dependency resolutions, mock target import paths, op handler invocations, or test materialization. The latter all used to be LLM-authored. The former are what’s left.
A concrete case: when the end-of-ticket Reviewer caught what every structural gate missed
A recent run produced code for a chain ticket against the project’s TypeScript monorepo. Type-check passed. The full test suite passed. The end-of-ticket Reviewer flagged four blockers and rejected the diff.
The four blockers, summarised from the Reviewer’s redo brief: an unused variable declaration in the route handler, two unused destructured variables in one helper function, two more in two other helpers, and a missing trailing newline at the end of one file. Three of the unused variables were destructuring patterns where the field already flowed through the surrounding parameter object, so the local variable was dead code. All four blockers would have caused biome ci to fail in the project’s lint pipeline.
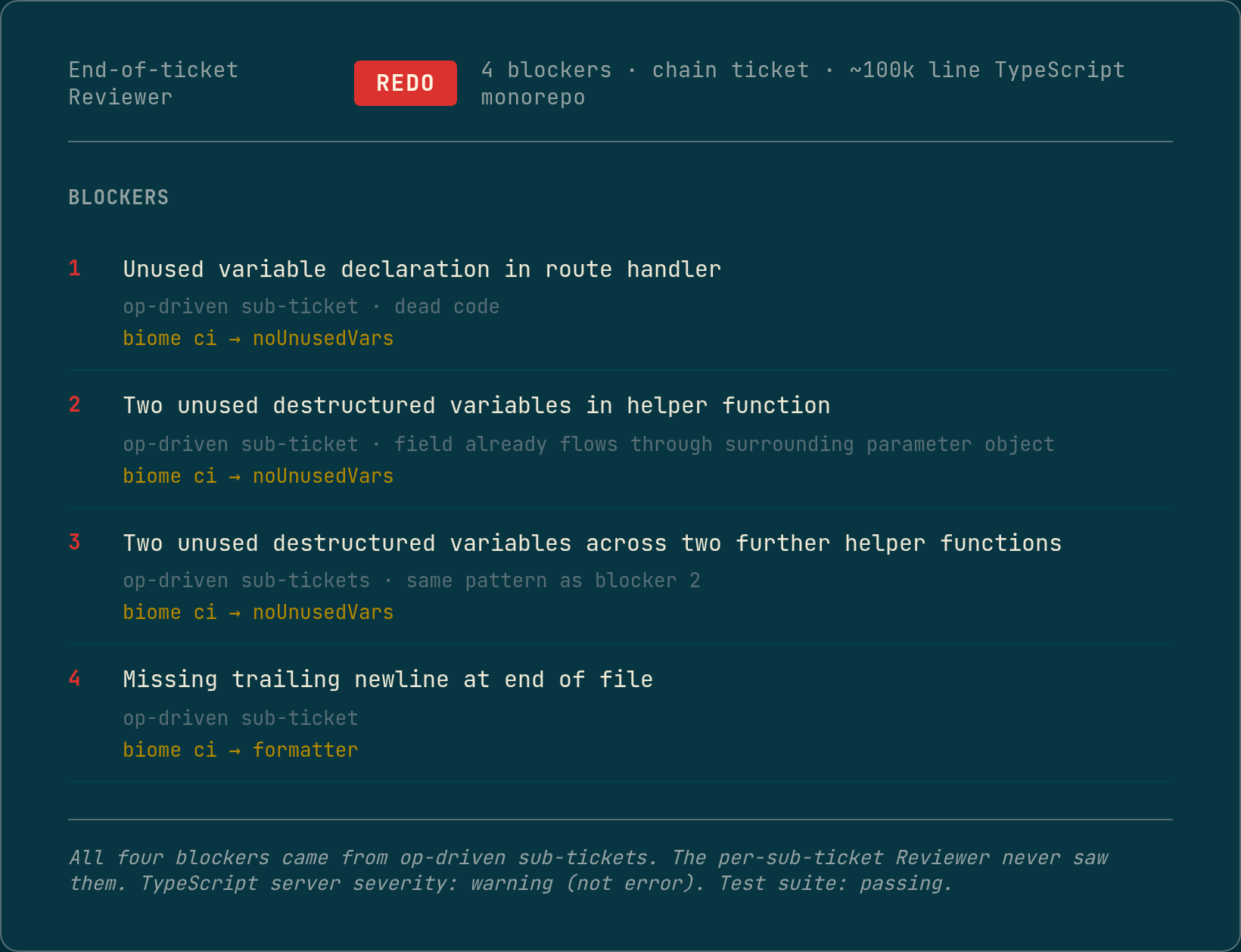
Why each upstream gate missed it. The TypeScript server classifies unused variables as a warning rather than an error by default, and the autofix pass at the time of the run only acted on type errors, not warnings. The test suite passed because dead destructuring doesn’t break runtime. The end-of-ticket type-check passed for the same severity reason as the per-write gate. The Reviewer caught it because Biome’s noUnusedVars rule is stricter than the TypeScript server’s defaults, and the Reviewer reads the diff and recognises the pattern.
The previous pipeline ran a Reviewer per sub-ticket, but it skipped op-driven sub-tickets, where deterministic operations replaced the Coder cycle and clean language-server diagnostics counted as auto-approve. The four blockers above all came from op-driven hops in this chain, which means the per-sub-ticket Reviewer never saw them. The end-of-ticket Reviewer reads the cumulative diff regardless of which sub-tickets came from the LLM Coder versus deterministic ops, and caught what would otherwise have shipped to CI.
This is exactly the Layer 3 backstop case. Layers 1 and 2 don’t apply because the dead destructuring is creative authoring at the implementation layer, not a structural fact the pipeline could have computed deterministically. Layer 3 caught it. The run also pointed at a follow-up gap. The pipeline should have a deterministic lint gate doing this work, so the Reviewer can stop spending its LLM judgment on what a linter could catch for free. That gap is filed. It’s the next session’s priority.
Architectural argument now, empirical replication later
What this post claims: the architecture is structurally less dependent on the LLM’s dice rolls than three weeks ago. The Synthesizer, the feasibility gate, the chain-selection and decomposition components, the transformer layer, and the end-of-ticket Reviewer move decisions out of the LLM, validate-and-rewrite where the LLM still authors, and add a structural backstop above everything. One worked case shows the backstop catching a bug class that would otherwise have shipped.
What this post does not claim: that the first-pass success rate has measurably improved against the original 248-run measurement. The headline 21 percent number has not been re-measured against the new pipeline. That’s a separate, future post and a separate, future measurement. Anyone reading this looking for “I went from 21 percent to X percent” should know the answer is “I don’t know yet, by design.”
The architectural argument stands on its own and is verifiable from the code today. The empirical claim deserves its own post and its own measurement.
What’s still on the to-build list
Several structural gaps remain.
The end-of-ticket type-check is currently scoped to the files the ticket touched. It doesn’t catch cross-sub-ticket type regressions in untouched dependent files, a real failure mode that the next architectural piece (reverse-dependency closure via the registry’s caller-analysis data) will close.
The test file is itself an unchecked oracle. No language-server autofix runs on it before the initial red-test confirmation. No semantic Reviewer pass evaluates whether the test correctly expresses the AC’s intent before the implementation Coder cycle uses it as the ground truth. The architectural shape is two distinct Reviewer LLM stages, one for the test (oracle quality), one for the implementation (oracle satisfaction). The Behavioral Oracle covers where that design landed.
The case study above identified a structural lint gate the pipeline doesn’t have: a deterministic Biome / ESLint / Prettier check before commit, alongside the existing language-server type-check. That’s filed and prioritised for the next session. It moves “Reviewer catches lint issues” from “LLM judgment lucky catch” to “structural enforcement, deterministic by construction.”
And the empirical replication itself. A comparable batch of tickets through the new pipeline, same fixture distribution as the original 248, same four-bucket classification. That’s the headline measurement that lets us say whether the lower dependence on lucky LLM rolls actually moves the first-pass success rate.
The architecture is in place. The 248-run replication is what comes after.
The pipeline runs against a TypeScript blog fixture and a ~100k line TypeScript monorepo. The run discussed above is a single case study, not a measurement. Still R&D.