What this post is
A new stage landed in this autonomous engineering pipeline: a grounding chat that runs before the pipeline begins its autonomous run. The operator answers a fixed set of structured design questions interactively, the chat captures the answers as a machine-readable handoff, and the downstream pipeline treats that handoff as load-bearing ground truth. The pipeline is still autonomous after the handoff.
The motivation is straightforward. The pipeline has been removing the LLM from decisions the project’s existing data can answer across the four architectural eras captured in the previous post. What that work could not remove was the LLM’s role in inferring operator intent from prose. When a single English ticket says “thread a flag through these layers and skip processing when it is true,” the LLM has to decide what the operator meant by “these layers,” “skip processing,” “this short-circuit boundary.” Hallucination on intent is a different failure surface than hallucination on placement, and the prior eras did not address it.
The grounding chat addresses it directly. Instead of asking the LLM to read the operator’s mind, the chat asks the operator a few specific questions and writes the answers as structured facts the pipeline can read. This post is what the grounding chat does, why it changes the trust hierarchy of the pipeline, and what landed downstream to make the new top layer of that hierarchy load-bearing.
What a grounding chat is
The grounding chat sits between the operator and the autonomous pipeline. It is not a conversational AI assistant. It is an interactive stage scoped to a fixed set of design questions: the LLM proposes an answer with rationale, the operator can accept it, decline it, push back with alternative reasoning, or ask follow-up questions, and each question’s exchange iterates until the operator confirms a specific resolution. The output is a structured handoff file with three load-bearing fields:
- Intent. What is being threaded, what kind of operation it is (a new field on a request, a new flag through a call chain, a new schema variant), what symbol the operator named as the entry point, what symbol they named as the target. None of these are inferred from prose. They are operator-confirmed at chat time.
- Exclusions. Symbols the operator explicitly told the chat not to touch, even when the LLM proposed touching them. The chat presents the LLM’s recommendations and the operator can decline them. Declined recommendations become exclusions in the handoff, with the original LLM proposal recorded alongside for traceability.
- Design decisions. Operator-confirmed resolutions to specific design questions the LLM raised. The settled resolution is what the handoff records, with the original LLM proposal alongside for traceability. Example: “the schema is a discriminated union with three variants. The new field could go on all three or only on one. Which?” The recorded value is the operator’s answer after whatever back-and-forth the operator wanted, not whichever option the LLM offered first.
The structure is machine-readable. Every downstream stage of the pipeline can consume it without parsing English. Stages that previously had to infer operator intent from prose can now read the answer directly.
The “grounding” part of the name is the bidirectional correction. The chat does not just record what the operator says. It cross-checks every load-bearing answer against the registry and the language server, and surfaces discrepancies before the operator confirms. The canonical example from this session: the operator named the entry point as /actions, the chat checked the route table and found no route at exactly /actions, but did find /api/items/actions (composed at runtime from a parent router mounted at /api plus a child router at /items plus the registered route at /actions). The chat asked the operator to confirm the resolved wire URL, the operator confirmed, and the structured handoff recorded /api/items/actions as the entry point. The downstream pipeline never had to guess what the operator’s /actions meant, because the chat had already grounded the operator’s answer in the registry’s actual route table.
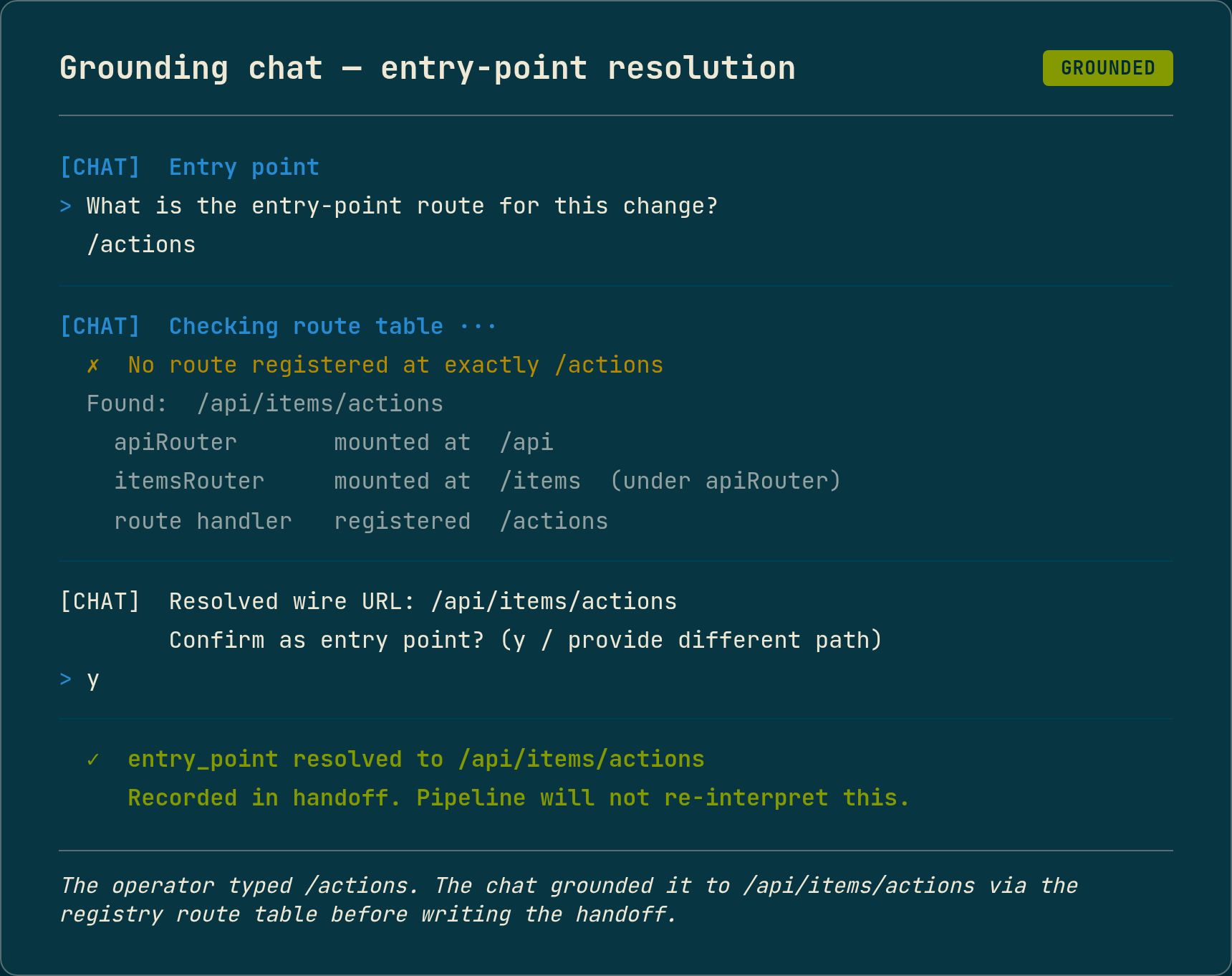
This direction matters as much as the conversational direction where the operator shapes the LLM’s proposals. Without the cross-check, the operator’s chat-authored design would still be a thing the LLM had to interpret against reality, just at a different stage. With it, the answers in the handoff are guaranteed to refer to symbols the pipeline can actually find.
Alongside the bidirectional correction, the chat runs a basic duplicate-work check before the operator answers any design questions. If a symbol matching the operator’s stated intent already exists in the registry, the chat surfaces the existing implementation and asks whether the new request is genuinely different. At the time of writing this check is narrow: direct symbol-name matches and obvious shape overlaps against the registry. It is not yet a hardened layer that catches semantically equivalent code at a different path, near-duplicate API surfaces, or subtler restatements of work that already shipped. Useful as a sanity gate today; not yet a comprehensive prevention layer. This is one of several places in the chat where the current implementation is intentionally narrow and the hardened version is on the work list.
The chat itself uses LLM calls for the recommendations and for proposing the structured questions. The LLM is non-deterministic in the words it chooses and the rationale it offers. What it cannot do is reference a pre-existing symbol the codebase does not have. New symbols the ticket is introducing are obviously not in the registry at chat time, and the chat proposes names for them based on the prose and the surrounding code’s conventions; the operator can accept the proposals or push back, same as any other design decision. The constraint is narrower than “no new names”: every pre-existing function, type, route, or schema the chat-authored design references must resolve to a real registry symbol. The LLM’s information about pre-existing code structure comes from the registry, and the chat-stage environment offers no path for the LLM to refer to a symbol the registry does not have.
The handoff is not “hallucinations the registry caught after the fact.” It is “the LLM was never in a position to hallucinate the existing code’s shape in the first place.”

Why this matters: the trust hierarchy gains a new top layer
The pipeline’s prior trust hierarchy, captured in the Data Path Principle, had three tiers: machine-extracted data outranks model-generated constraints, which outrank model narrative. The pipeline derives facts from the source code, the registry, and the language server; the LLM contributes constraints and narrative on top of those facts.
The grounding chat adds a new top layer to the hierarchy:
human chat-authored design outranks machine-extracted data, which outranks model-generated constraints, which outrank model narrative

The chat handoff is human-authored ground truth. Machine-extracted data remains second-best, useful when the operator did not specify something or when the operator’s specification contradicts the source (in which case the source wins because the source is what compiles and runs). LLM narrative remains the lowest layer, useful when neither the operator nor the data has the answer.
The reason this matters is that the pipeline already had deterministic builders built specifically to override LLM narrative when machine-extracted data disagreed. Those builders carried hardcoded opinions about where threading fields belong, what an “options bag” looks like, what destructure access path to author. With LLM-only authoring upstream, those opinions had been correct-by-construction. The LLM hallucinated placement details in well-known ways, the builders corrected the hallucinations.
When the operator entered the loop, those same builders started overruling the human’s design. The operator was not wrong; the builders did not know there was a new top of the trust hierarchy they had to consult first.
What the chat changed downstream
Adding the grounding chat on the chat side was the easy part. The downstream pipeline had to learn that there was a new top of the trust hierarchy to consult.
The illustrative case is the request-body relocation rule. The pipeline had a deterministic builder that, when the LLM authored a field at a request body’s top level that the schema did not declare there, moved the LLM’s placement into a nested options bag. This was the right move when the LLM was the only authorial layer upstream: the LLM hallucinated nesting depth in well-known ways, the builder corrected the hallucinations. On this ticket the operator’s chat-authored design explicitly placed the field at the top level. The authoring stage faithfully transcribed the design. The relocation rule overruled it, and the downstream code wired the wrong access path. Type errors at LSP gate.
The fix is small: the relocation builder defers to operator design when a grounding chat ran, with unchanged behaviour on non-chat-authored paths (hand-written tickets, CLI-direct invocations).
Five other deterministic builders needed the same treatment across the same eight pipeline runs. Each had the same shape: a hardcoded heuristic that had been correct for LLM-only authoring stopped being correct when the operator entered the loop. Each fix taught the builder to defer to operator design when present, with unchanged behaviour when no handoff exists. The work was bounded and the pattern repeats; the broader audit of remaining builders is filed as an open architecture gap rather than swept speculatively now.
What an end-to-end run looks like
The first pipeline run that cleared every deterministic-builder gate end-to-end came after the six fixes landed. The same operator-authored ticket that had failed in different ways across the previous seven runs ran chat through ticket-generation through the autonomous loop and produced four committed sub-tickets, an LSP-green codebase, a project-linter-green codebase, and 958 of 959 full-suite tests passing.
The cost broke down across three phases:
| Phase | Wall share | Cost |
|---|---|---|
| Grounding chat | ~21% | $0.194 |
| Ticket-generation | ~11% | $0.254 |
| Autonomous loop | ~68% | $0.233 |
| Combined | 100% | $0.681 |
The grounding chat dominates wall-time among the human-facing stages. That is by design. The operator answers design questions with the LLM proposing each one, the handoff is written, the autonomous pipeline takes over. The operator does not return to the loop until the pipeline either commits the work or surfaces a failure.
The autonomous loop’s $0.233 is comparable to the prior era’s cost on the same ticket family, despite running a full 958-test vitest sweep at end-of-ticket (the prior era’s 9/9 number was ticket-specific, not full-suite). The grounding chat’s $0.194 and the ticket-generation’s $0.254 are roughly the same order of magnitude as the prior cost-per-test numbers, which is consistent with the chat doing genuine LLM work: proposing recommendations, structuring questions, parsing operator responses.
What is still LLM judgment
The one remaining test failure on this end-to-end run was inside the Coder, not inside any deterministic builder. The operator’s ticket asked for a short-circuit pattern across three branches of a function: status guard, then flag check with early return, then side-effecting calls, then success return. The Coder authored two of the three branches in the correct order. In the third, the Coder placed the early return after a destructure of a side-effecting call’s return value. When the flag short-circuits the call, the destructure runs on the would-have-been-returned value and throws.
This is not the grounding chat’s job to prevent, and it is not a deterministic builder’s job either. The change is genuinely behavioural: the function’s body is rewritten with new control flow, and the pipeline correctly delegates that to the LLM Coder. What the grounding chat did was tell the pipeline precisely what to delegate, which side-effecting calls were the short-circuit boundary, which branches needed the guard. The Coder had all that information. It still got one branch wrong.
A non-deterministic mitigation landed this session: a new Coder authoring rule about guard ordering and destructure positioning. The deterministic follow-up is filed as a future architecture gap with three design options of escalating scope. Whichever one ships, the principle is the same as the rest of the grounding-chat work: when the operator’s design specifies an ordering, the pipeline should not be asking the LLM to re-derive it.
What this is not
The grounding chat is not “human-in-the-loop” in the conversational-AI sense. The operator answers a fixed set of structured design questions during a session, and the autonomous pipeline runs without further operator intervention. The human is upstream of authoring, not embedded in execution. A conversational chatbot that the pipeline calls back to mid-run would be a different architecture with different tradeoffs.
The chat is not a replacement for the operator writing a clear ticket. The chat is a different way of capturing what would otherwise be in the ticket prose. The operator still spends roughly the same effort framing the change, just as structured answers to specific questions rather than as a paragraph of English. The benefit is not less operator effort, it is operator effort that the pipeline can read directly without the LLM having to infer.
The deterministic builder fixes are not finished. Two architecture gaps remain open, one for a broader audit of remaining builders that may carry the same shape of hardcoded opinion, one for a deterministic operator that would replace the Coder fall-through entirely on tickets shaped like this one. Both are deferred until the next failure rate justifies the build cost.
The pipeline runs cited in this post are from a single session, all consuming the same chat handoff produced by one upstream chat session. They are not a benchmark. They are the same operator-authored ticket on the same TypeScript codebase, run iteratively while one fix per failure shape was landed. Not every fix was about the grounding chat itself; some were pre-existing pipeline bugs that surfaced because a chat-authored ticket happened to exercise them. The chat-specific work was the subset where a deterministic builder had to learn to defer to operator design. The trajectory is real evidence, not a leaderboard position, and the prior eras of pipeline work did not have a grounding chat at all.
What the grounding chat does is take the LLM out of the role of guessing what the operator meant. Tickets that used to be a paragraph of English the LLM had to interpret are now a short structured exchange where ambiguities surface before any code is written. A vague ticket gets caught at the chat stage; a precisely written one gets a sanity cross-check against the codebase the operator wrote it about. Either way the operator spends some upfront time confirming what the pipeline is about to do, instead of watching the pipeline produce something they did not actually want. Every downstream stage of the autonomous pipeline now has access to operator-authored ground truth at the top of its trust hierarchy, ahead of machine-extracted data and well ahead of LLM narrative. The architecture’s defence against hallucination has gained a layer it did not have before, and the layer is the operator’s own design rather than a stricter LLM rule.
The pipeline runs inside Docker on real tickets against a ~100k line TypeScript monorepo. The grounding chat landed across two sessions of work, with the deterministic-builder de-opinionisation arc spanning eight consecutive pipeline runs of the same operator-authored ticket. Still R&D.