An earlier post on this pipeline described a ladder of ticket shapes, climbed one rung at a time, each rung a different decomposition rather than a different parameter. It listed five rungs and stopped at four. Additive flags, removal, multi-flag, and a greenfield endpoint had all reached full completion; Rung 5, rename and refactor, was deferred with a written trigger rather than half-built. This post is where Rung 5 got built. It is also where Rung 5 did what every rung in that post did: the green run was not the point; the gap it forced into the open was.
A green test suite tells you the code runs. It does not tell you the code type-checks. On a real codebase those are different facts, and an agent pipeline that treats them as the same will confidently “fix” errors it never caused. The gap Rung 5 exposed is exactly that. A gate read a passing suite as a clean type-check baseline, counted the target’s pre-existing language server (LSP) errors against a correct rename, and set off a token runaway chasing a problem that was never there. This is a post about LLM coding agents misattributing a target’s pre-existing type errors to their own change, why an absolute health signal is the wrong thing to gate on, and a second, stranger way a type-check can lie.
Rung 5: rename as a structural edit below the floor
What makes rename a ladder rung and not just another feature is the property that made the four zero-Coder shapes below it work: the change is a structural edit to code that already exists, so it belongs below the floor, the line under which work is deterministic and no model authors anything. A rename names a symbol and rewrites every reference to it as a machine edit. There is no new logic and no function body to write, which is exactly the property that keeps the Coder out of it.
The reference set comes from the registry, which combines language-server results for production code with a Tree-Sitter pass for the test files the production tsconfig excludes from its program. The first real rename was resolveSourceConfig to getSourceConfig across a real TypeScript monorepo: 30 reference sites, 21 in production code and 9 in tests, across 12 files. The structured operation rewrote every one of them on disk, verifiably. The declaration, every call site, every import, and all 9 sites in the test file. Unlike the additive and removal shapes, a rename has no behavioral oracle to confirm-RED against, and the completion bar is different here: the proof is structural completeness and a green suite rather than behavioral necessity, because a single missed reference leaves the old name dangling and breaks an import.
The symptom: a token runaway
The gate that lets a deterministic edit commit without invoking the Coder aborted after the rename, decided the tree was broken, and handed the work to the Coder. It did that the first three times. The rename was correct each time.
A rename has no function body to write, so the Coder had nothing legitimate to do. It emitted off-scope edits and retried, blowing past a per-file token ceiling of 700K and climbing to 985K before the loop gave up, having spent over 900K input tokens on a change that was already complete and correct. That 700K ceiling is a relic from the pipeline’s early, unoptimized days, left untouched as the architecture moved on, and it had not fired for any supported ticket shape before this. It fired here only because the false measurement pushed a deterministic edit into the Coder, the one situation that produces unbounded retries; a healthy ticket runs nowhere near it. The real hardening for that blast radius is separate work in any case: a deterministic edit should never reach the Coder, and the cap should terminate the loop rather than abort one call at a time. The runaway was a downstream symptom. The trigger was three “type errors” the gate read after the rename.
Reading the three type errors
shared/src/source-config.test.ts:1 TS2307 Cannot find module 'vitest' or its type declarations.
shared/src/source-config.test.ts:5 TS2305 Module './source-config' has no exported member 'resolveSourceConfig'.
integrations/source-b/src/run.ts:14 TS1470 'import.meta' is not allowed in files which build to CommonJS.None of the three was a real, rename-introduced break. They failed for two different reasons, and the two are worth keeping separate.
False green, first kind: a passing suite is not a clean type-check
The first and third errors have nothing to do with the rename. The Vitest module-not-found is a case where the test runner resolves Vitest fine at runtime but the language server’s view of that directory does not resolve its types. The import.meta error is a tsconfig module-target mismatch in one package. Both are pre-existing in the target’s baseline. They were there before the rename and would be there after it, and the suite passes anyway every day, because neither breaks anything at runtime.
The gate counted the absolute number of type errors after the edit. Non-zero meant “the edit broke the tree,” so it handed the work to the Coder. That assumption, a clean type-check baseline, is false for essentially every real project. The rename was already correct; the gate aborted it anyway by counting the target’s own standing noise against the change.
False green, second kind: a language server asked about a file outside its program
The middle error is the strange one. The test file at line 5 reported resolveSourceConfig, the old name, as a missing export, even though the edit had verifiably rewritten that line to getSourceConfig. How does the type-checker report the pre-rename name against a post-rename file?
I chased it as a timing bug for three attempts: forcing re-validation after each edit, gating on document version, and adding a synchronisation barrier before querying. None cleared it. The reframe came from one measurement: every type-check call returned in about 0.01 seconds. The language server was not re-validating anything. It was serving a cache. The 11 production files cached correctly with zero errors. Only the test file cached stale.
The reason is structural. The test file is excluded from the production tsconfig program. The long-lived tsserver the gate queries never had that file in its program, so it never re-validated it on edit and handed back a stale result from before the rename. No amount of gate timing could fix that, because the file was never going to be re-checked by that server. The fix is to not ask a type-checker about a file it does not own. The production gate now scopes itself to the files the production program actually contains, and routes the test files to the tool that does own them: the test runner.
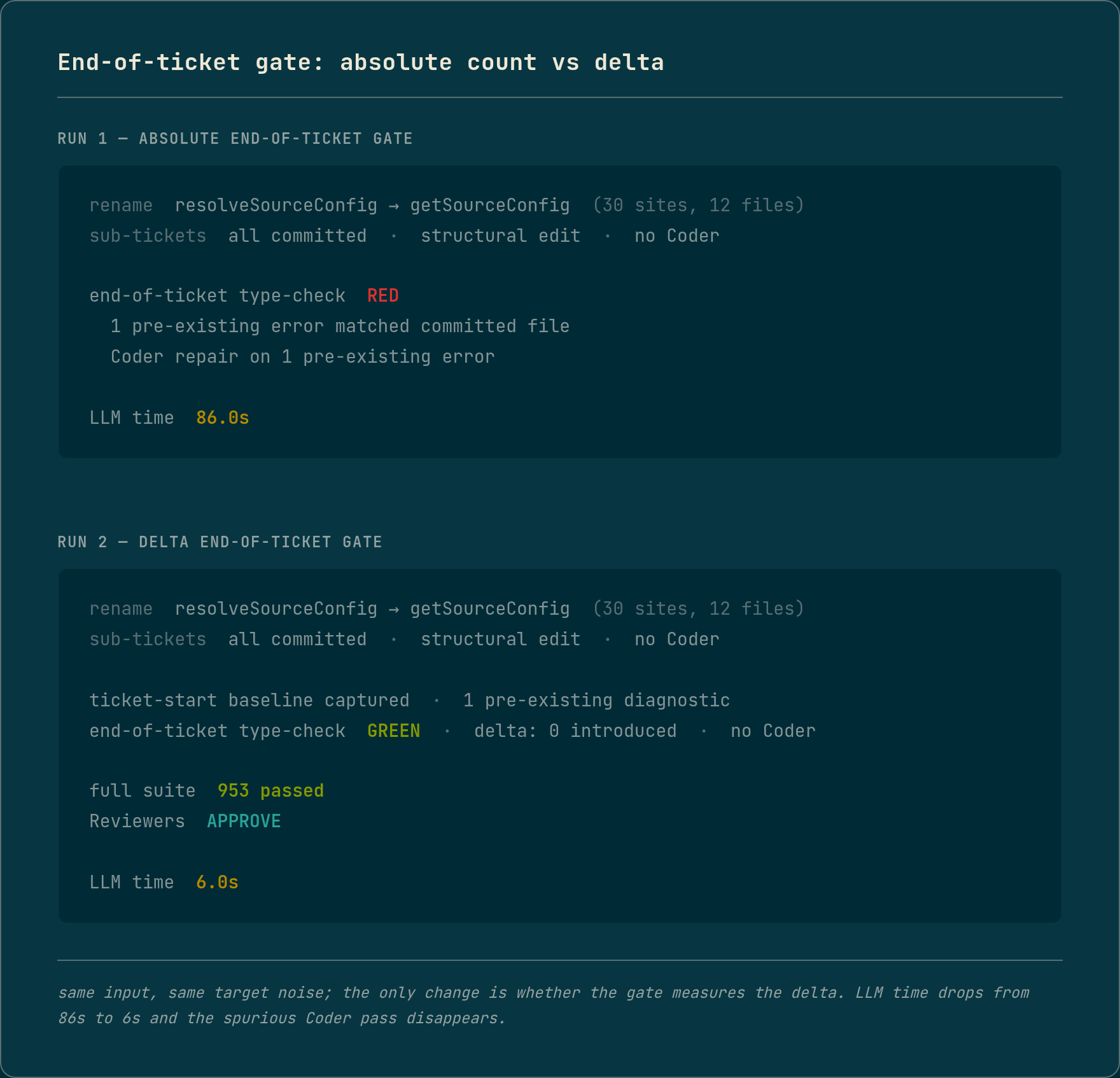
The fix: gate on the delta, not the absolute count
The phantom was a sideshow once I understood it. The load-bearing fix was simpler and more general: measure the delta. Snapshot the type errors before the change, and gate only on errors the change introduced. After it landed, the same rename produced the line you want to see: eight pre-existing errors detected and all eight correctly ignored as a zero delta, and the rename committed with no Coder involvement. That is the rename back below the floor, where it belonged.

The same gate bug at the end of the ticket
With the delta gate and the program-scoping both in, the rename completed for the first time. It was not clean. A second, coarser gate runs after every sub-ticket commits and re-checks the whole cumulative diff. That gate still counted absolute errors. It found the pre-existing import.meta error in a file the rename had merely touched (the rename rewrote two references there, which pulled it into the cumulative-diff scope) and fired a one-shot Coder repair on it. The Coder rewrote a file to fix an error the ticket never caused, spending 80 seconds and about 28K tokens. That run stayed green by luck. On a less lucky ticket, an unrelated rewrite of unrelated code is a regression waiting to happen.
The per-sub-ticket gate was delta-aware. The end-of-ticket gate was not. It was the same bug in a second place, and the fix was the same: capture a baseline on the clean tree before any sub-ticket runs, and subtract it. The clean run after that fix dropped from 86 seconds of LLM time to 6, did no Coder work, type-checked green directly, passed the full suite of 953 tests, and both Reviewers approved.
What the rename cost
End to end, grounding chat through the clean loop, the rename ticket cost about $0.56 in model calls at list prices: roughly $0.21 for the grounding chat, $0.28 for ticket generation, and $0.07 for the Reviewer. The structural edit itself, 30 reference sites across 12 files, ran no model and cost nothing. The spend sits in the design stages and the final review, which is where it belongs. These are list-price estimates on a subscription rather than metered; treat them as order of magnitude, not an invoice.
The figure is worth stating because of the contrast inside it. Before the delta fix, the spurious end-of-ticket Coder pass cost about $0.24 on its own, more than three times the $0.07 the correct rename cost, and it was spent rewriting an unrelated file to fix an error the rename never caused. A false measurement does not only cost wall-clock time. It spends real money on work that should never have run.
Against the engineer-minutes a codebase-wide rename across 12 files would otherwise take, including the test files an IDE rename would skip, $0.56 is cheap. It is not optimized: almost 90 percent is the two design stages, and neither has been optimized for a while. The current priority is correctness and feature coverage, not cost, and the number will shift as the pipeline matures and those priorities move.
The reason to write the cost down is that cost per ticket is the unit that decides whether an autonomous pipeline is worth running, and a pipeline that silently triples a ticket’s bill chasing a phantom is failing in a unit the test suite never reports.
Two kinds of false green
False green has at least two faces here, and both are the measurement being wrong rather than the code.
The first is that a green suite is not a clean type-check. Real targets carry pre-existing type errors, lint warnings, dead code, and config mismatches their suite never surfaces. Any gate that reads an absolute health signal misattributes that standing mess to the current change. The fix is to gate on the delta. The cost-of-ownership lesson is that this is not a one-line fix in one place: the same absolute-versus-delta bug hid behind two separate gates, and finding the second one took a clean run to expose. A gate that reads absolute state is worth auditing everywhere it appears, not just where it first bites.
The second is that a type-checker asked about a file outside its program returns a phantom. The production language server excludes test files, and querying it about one returns a stale, inferred answer that looks exactly like a real error. The fix is to scope each gate to what its checker actually owns and route the rest to the tool that does.
There is a deliberate limit still standing. Type-only errors in a test file, the kind the runtime suite would not catch, now fall outside both gates, because the production type-checker does not own those files and the test runner only catches what breaks at execution. Closing that needs a dedicated test-program type-check, which is deferred until a real case for it appears. It is a known gap, recorded as such, not an oversight.
When a deterministic stage trips an LLM-fallback gate, that is a signal a measurement is probably lying, not a cue for the model to start typing.
That is the thread tying all of it together. A rename has no body to write, so a Coder being asked to “fix” one is the system reporting that it mismeasured. This is also the argument the ladder post kept making, one rung at a time: the value of climbing a shape was the gap it exposed, not the green checkmark. Rung 5’s gap was a gate that trusted a baseline that was never clean, and it surfaced only because the target was a real, green-but-messy codebase rather than a pristine fixture. A clean fixture has no pre-existing errors to misattribute and no excluded files to phantom on, so it hides exactly the failures a real codebase forces into the open. This is one TypeScript monorepo, and still R&D.

The pipeline runs inside Docker on real tickets against a ~100k line TypeScript monorepo. Still R&D.