A pipeline run hit a generated test that wouldn’t compile. The wrapping exception in the test-rendering layer read (paths and symbol names anonymised; structure verbatim):
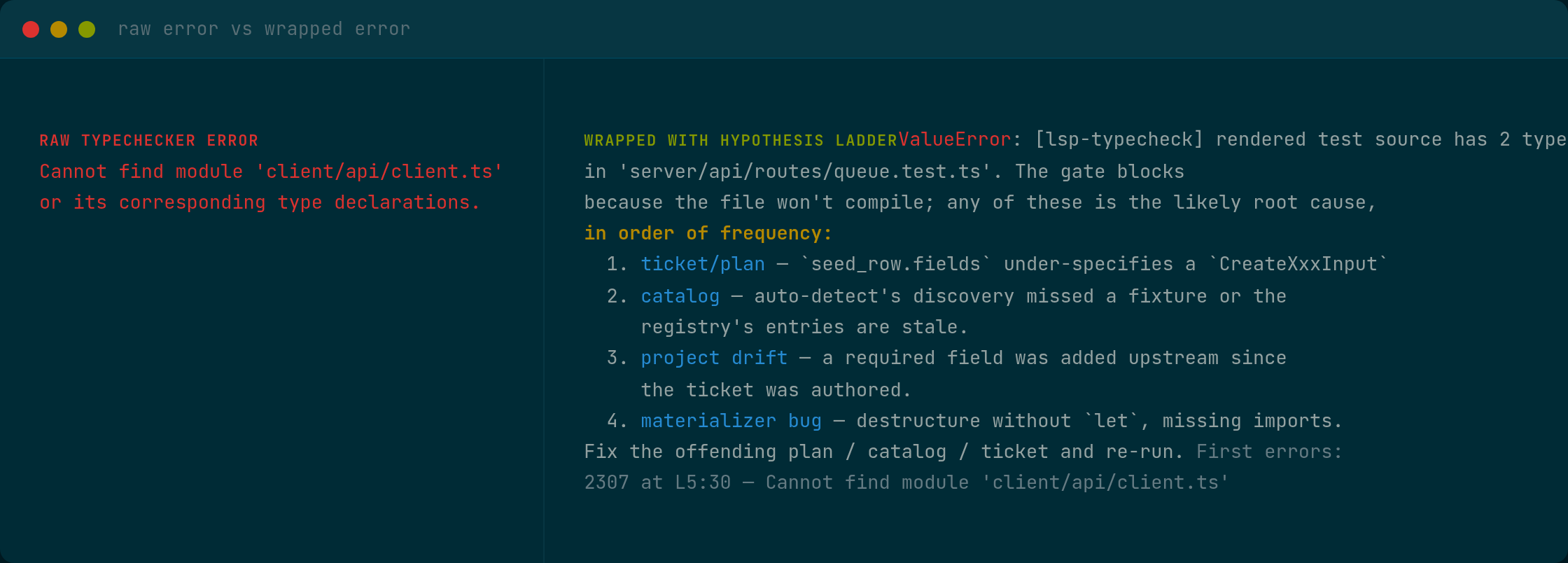
ValueError: [lsp-typecheck] rendered test source has 2 type error(s)
in 'server/api/routes/queue.test.ts'. The gate blocks
because the file won't compile; any of these is the likely root cause,
in order of frequency:
1. ticket/plan — `seed_row.fields` under-specifies a `CreateXxxInput`
(missing required field); `match_args` shape mismatches the mocked
fn signature; `${capture.field}` references a field that doesn't
exist on the capture's type.
2. catalog — auto-detect's discovery missed a fixture or the
registry's entries are stale; repo helper's actual
signature drifted from the registry entry.
3. project drift — a required field / type was added upstream since
the ticket was authored.
4. materializer bug — destructure without `let`, missing imports,
wrong fixture-call shape.
Fix the offending plan / catalog / ticket and re-run. First errors:
2307 at L5:30 — Cannot find module 'client/api/client.ts'
or its corresponding type declarations.Without the categorized hypothesis ladder I would have opened the wrong subsystem first. With it, I went straight to category 1, “ticket/plan.” I opened the ticket, found a mock with the bad import path, and chased it back to the upstream stage that wrote that path. The actual fix took about ten minutes.
I want to write down what makes this error message good. I think the technique generalizes, and matters more, not less, as more debugging is done by AI agents.
Why the raw error message isn’t enough
The default form for this kind of failure would have been the raw language server (LSP) error: Cannot find module 'client/api/client.ts'. That’s true. It’s also useless. It tells you that an import is wrong. It doesn’t tell you:
- Which subsystem produced the wrong path (the LLM that authored the ticket? the test-rendering layer? a stage that rewrote the path between those two?).
- Whether this is a class of bug you’ve seen before, or something new.
- What to do next.
A wrapping error that hides the raw signal would also be bad. You’d lose the 2307 code, the L5:30 location, and any ability to dig further. So the goal is wrapping that adds without subtracting.
Five techniques that make a wrapping error useful
Looking at the artifact above:
1. Frequency-ordered root-cause ladder. “in order of frequency.” Three words doing a lot of work. They encode operator experience. Over many failures of this kind, here is which class usually turns out to be at fault. The reader gets a search order, not a list. Most error messages either give you nothing or give you everything with no priority; this one tells you where to look first.
When that ordering is right, you’re done in minutes. When it’s wrong (the actual cause is #3), you’ve spent the time to rule out #1 and #2, which is also useful, because now you know what it isn’t. The ladder is robust to being wrong; it never costs more than checking categories in series anyway.
The structure resembles Bayesian debugging: the frequency ordering acts as an empirical prior over failure causes, maintained by hand rather than computed from logged frequencies. Start where historical base rates are highest, update as you rule each hypothesis out.
2. Categorization by subsystem, not by symptom. The four categories name layers of the system: ticket/plan, catalog, project drift, materializer bug. That tells you which file to open first. Symptom-based wording (“missing field,” “type mismatch”) would route you to the type of bug, not the location of it.
This matters because in a large pipeline, the same symptom, “compile error in generated test,” can be produced by half a dozen different subsystems. The TypeScript compiler doesn’t know which subsystem wrote the offending line. The wrapping error does, because it was placed by the engineer who knows the pipeline architecture.
3. Raw diagnostic preserved at the bottom. First errors: 2307 at L5:30 — Cannot find module 'client/api/client.ts'. The TypeScript error code and source location survive intact, after the categorized explanation. If category 1’s heuristic is wrong, you still have the original signal to dig further.
This is a small thing that lots of error wrappers get wrong. They paraphrase, lose precision, and force you to git grep for the original wording. Keep the raw error inline.
4. Closes the loop with an action. “Fix the offending plan / catalog / ticket and re-run.” A verb and a scope. Most exceptions stop at “here is what’s wrong”; this one tells you what to do. The action also implicitly confirms a model: the pipeline expects you to fix the upstream artifact (the ticket or the plan), not the downstream output (the generated test).
In my pipeline that’s critical. If you tried to fix the generated test directly, the next loop iteration would overwrite your fix. The error message saves you from that mistake without having to say it explicitly. (When the prescribed action is non-obvious, name it explicitly. I get that wrong in other error messages.)
5. Same message serves both human and machine debuggers. This one isn’t always relevant. For an agent pipeline like this one, the same error gets read by an autonomous loop that re-attempts the failed work. A frequency-ordered, categorized ladder is much more useful to an LLM than a raw stack trace. The model can pick a category and act on it, instead of trying to reconstruct your pipeline architecture from scratch each iteration.
This is the part of the technique I think is most underexplored in 2026. Most “good error message” writing predates the agent era. The advice still holds. The audience has expanded, and a message designed for both audiences tends to be better even for the human one.
Walk-through: from typechecker error to root cause in ten minutes
Here’s the actual debugging path the error enabled.
The first errors line said Cannot find module 'client/api/client.ts'. A reasonable first guess from the raw error alone: “the path is mistyped, fix it.” That would have routed me toward the test-rendering layer, the subsystem that writes import statements into the generated test source.
The ladder said: try ticket/plan first. So I opened the generated ticket, looked at the mocks, and found the offending import path was authored not by the LLM directly but by a downstream pipeline stage: the one that rewrites mock import paths to their canonical defining-module specifiers. That stage had picked client/api/client.ts for a function called summarizeRecord. The target project has a function with that name in both client and server modules, and the stage’s symbol lookup resolved multi-definition symbols using a heuristic that silently picked one, with no guarantee it was the right one.
Once I had the right subsystem, the fix was short: route the stage’s lookup through the project’s existing symbol resolver, which already distinguished multi-definition symbols and surfaced them as ambiguous. Ambiguous paths are now preserved rather than collapsed. The fix required three new tests and a wider gate.
If I had started with the test-rendering layer, I would have been reading an entirely different module for an hour before remembering that mock imports get post-processed.
What hypothesis-ladder errors cost to maintain
Hypothesis ladders are not free. They require maintenance.
- The frequency order rots. If you fix the bug that caused most “ticket/plan” errors, category 1 should drop in the ranking. If you don’t update the message, you mislead future readers. I re-order when I close a known issue that significantly shifted failure frequency.
- New categories appear. When a new subsystem is added that can produce this error, it needs to enter the list. If the wrapper isn’t audited periodically, it grows stale silently. Stale categorization is worse than no categorization, because it lies with authority.
- Wrong categorization is high-cost. A miscategorized error sends the reader confidently to the wrong subsystem. Be willing to ship a vague ladder rather than a confident wrong one.
Stale categorization is worse than no categorization, because it lies with authority.
The maintenance cost is real but bounded. The wrapping site is one place, and updating it on each adjacent landing takes a minute. I treat it as part of the post-fix checklist.
One honest limit on the broader claim: the evidence here is one error class in one pipeline. Frequency-ordered hypothesis ladders are established practice in compiler diagnostics (Rust, Elm, see below) and I now believe they are worth the maintenance cost at runtime as well, but “worth it” for a typechecker-wrapping exception is not the same evidence as “worth it for every exception class in your system.” If you adopt the pattern, expect to learn which classes of error pay back the wrapping work and which don’t. I have not run that experiment broadly yet.
Prior art: error messages in Rust, Elm, and modern Python
The technique isn’t new at compile time:
- Rust’s compiler errors with
E0382-style codes, suggestions, and “consider doing X” hints. Frequency-ordered hypotheses, source-located, action-suggested. - Elm’s “compiler-as-editor” errors, the famous paragraph-style errors that read like a colleague explaining the problem.
- Python’s PEP 657 column-precise tracebacks, a small improvement representative of the broader move toward errors that locate the bug as precisely as possible.
The runtime equivalent, exception messages designed with the same care, is rarer. Most engineering shops still treat exceptions as developer-only diagnostic strings, optimized for the original author’s recall, not for the next person (or agent) to read them.
When to use a hypothesis-ladder error message
You don’t need every error to use this pattern. Most errors are fine as one-liners. The category that benefits from a hypothesis ladder:
- Errors that can be produced by multiple subsystems with similar symptoms.
- Errors thrown from a layer that wraps something noisy (a compiler, a typechecker, a parser, a network call).
- Errors that an agent in a retry loop will see and need to act on.
For those, write the wrapper once. Order the categories by what you’ve actually seen. Keep the raw signal at the bottom. Name the action. Audit the ordering when the failure-mode landscape shifts.
The cost is small. The next debugging session it saves, whether yours or your agent’s, pays for the wrapper many times over.