An earlier post on this blog, Why the Debugger Never Inherits the Coder’s Reasoning, ended on a list of things the Debugger could not do. It could not fix a wrong acceptance criterion: it would correctly diagnose the implementation as right and the test as wrong, and that diagnosis surfaced at the Reviewer or not at all. It could not recover from a manifest that scoped the wrong files: it would flag a failure it had no authority to repair, and the run halted. The diagnosis was precise. The dispatch was not. Every failure that was not a plain logic bug in correctly-scoped code hit the same wall.
This post is about closing that gap. In this pipeline the Debugger has become a diagnostic router. It still reads the test output, the failing code, and the manifest. What changed is what it does with the diagnosis: instead of one destination, it now picks the stage that owns the fix. A logic bug routes to the Coder. A failure caused by an incomplete manifest, a wrong test expectation, or a wrong ticket routes to the layer that authored that input. And a class of failures that used to terminate the run, most of the end-of-ticket gate failures, now route to a repair attempt on the cumulative diff; the rest still terminate, for reasons covered later.
The design work was not in building the router. It was in redrawing it against a pipeline that had already removed several destinations the first sketch assumed. The router was designed once against an earlier design, and most of what follows is the gap between that design and the version that runs today. It is also not finished: a meaningful piece of it is still unbuilt, and while some of its routes have fired on real runs, others have only been proven in tests. So this is the update, not the final word. A later post will report how the router behaves once it has been exercised on real failures. This one is about what changed between the first design and the version that runs today, and why.
What the Debugger could route to before: one place
The Debugger is not a monitor watching the pipeline, and it is not always running. A green run, where every stage produces what it should and every gate passes, never invokes it at all. The Debugger only runs when something has failed: a Coder attempt fails one of its post-write checks (the generated code is malformed, types break, lint rejects it, or tests go red), an end-of-ticket gate rejects the cumulative diff, or a pre-Coder operation fails to apply. When that happens it steps in, reads what happened, and decides where the work should route. For a Coder failure that means handing the Coder a corrective brief and another attempt, not waiting until the budget is fully exhausted before diagnosing. An earlier post in this series described it as firing only after the retry budget runs out; that described an earlier state. The current design runs it on each failed attempt so the correction reaches the Coder while retries remain. The rest of the time, it does nothing.
When it does run, two things distinguish it from every other stage. The first is the information it sees, which no other stage sees in full. It reads everything that triggered it plus the context the failing checks themselves don’t have: the manifest and the full attempt history across the Coder’s tries, all at once. Other stages each get a slice: the Impl Reviewer reads the final diff at the end-of-ticket boundary, a gate sees only its own pass or fail, the Coder sees its current task. Only the Debugger sees the whole runtime picture, including what changed between attempts and why each one failed. That breadth is what lets it name not just that something failed but which stage’s input was responsible.
The second distinction is the one that matters most for this post, and it is absolute. The Debugger is the only stage that can change where the pipeline goes next. Every other stage emits a verdict or an output that the pipeline’s fixed control flow then consumes: the Reviewer returns approve or reject, the Coder produces a diff, a gate passes or fails. None of them chooses which stage runs next. The Debugger’s output is the routing decision itself, a choice of which stage owns the repair.
The stage with the widest view is also the only one allowed to redirect the pipeline, which is exactly why a wrong diagnosis here is more dangerous than a wrong verdict anywhere else.
What the Debugger did with that evidence and that authority, before the router, was simple. It produced a structured diagnosis, and that diagnosis had exactly one consumer. If the Debugger decided the code was wrong, it handed a corrective brief to the Coder for another attempt. If it decided anything else, the diagnosis was correct and useless: the Coder cannot fix a wrong test (a write gate forbids it, for good reasons covered in the earlier post), cannot widen a manifest, and cannot rewrite a ticket. So those diagnoses produced more Coder attempts against a problem the Coder structurally could not solve, until the retry budget ran out and the run terminated.
Named the way this pipeline names it, that pattern is the builder doing brain work. The Brain layer / builders boundary says all searching, locating, and deciding belongs upstream; if a builder is doing any of those things, that is brain work leaking downstream and the upstream input was incomplete. Pushing the decision back is the answer, not prompting the builder harder. The pre-router design did the opposite: each repeat Coder attempt against a wrong test, a wrong manifest, or a wrong ticket asked a builder to compensate for an input it had no authority to change.
That is what the router replaces. The diagnosis was already rich enough to name the owning stage. The pipeline just had no channel to send it there.
The router is three surfaces, not one loop
The first correction the design needed was that this is not a single loop. Conflating the loops was the central error of the original design. The router operates across three distinct failure surfaces.
The pre-Coder op stage runs before any LLM. A sub-ticket’s mechanical edits, the typed deterministic operations the pipeline applies through Tree-Sitter and the language server (LSP), run first. If one of those typed operations fails, its error is structured: each failed operation produces a structured error naming the cause and the fix. That failure is now surfaced as a correction request rather than silently abandoning the sub-ticket.
The inner loop is the per-sub-ticket Coder loop the earlier post described. The Coder attempts the manifest; on failure the Debugger diagnoses; the diagnosis decides where the work goes.
The outer loop is the set of end-of-ticket gates that run after every sub-ticket has committed: a language server type-check, a linter, an optional build step, and the two Reviewers, all evaluating the cumulative diff. These catch cross-sub-ticket interactions that no single sub-ticket’s gates could see. Before the router, any of them failing terminated the run.

The four diagnoses the inner loop dispatches on
Inside the inner loop, the Debugger classifies each failure into one of four kinds, and the kind decides the destination.
The code is wrong. The manifest and the test are correct; the implementation does the wrong thing. This is the original path: a corrective brief naming what to fix and what not to retry, handed to the Coder for the next attempt, bounded by the retry budget.
The manifest is wrong. The instructions the Coder followed were incomplete: a missing symbol, a missing file, a constraint that does not match what the type system requires. No further Coder attempt will fix this, because the Coder is faithfully executing bad instructions. A deterministic backstop catches the obvious version of this: when the Coder reproduces an approach the previous attempt’s diagnosis explicitly flagged as wrong, the router auto-escalates rather than spending the rest of the budget on the same mistake.
The test expectation is wrong. The test asserts behavior the type system or schema contradicts: it expects a 400 for a field the request schema silently strips, or a status the route’s response type cannot produce. The implementation may be entirely correct.
The ticket is wrong. The ticket itself made a claim that machine facts disprove: it references a field absent from a known type, or a symbol that does not resolve. The manifest correctly transcribed a wrong ticket. Re-deriving the same ticket reproduces the same error.
Half the destinations no longer exist
The original design assumed each of those four diagnoses had a distinct repair stage to route to. A wrong manifest would route to the Planner for re-decomposition. A wrong test would route to a test-author stage for a re-run. The 248-runs follow-up post named exactly those destinations when it described this routing as the architectural piece still in flux: “Planner re-decomposition for manifest issues, Coder repair for code issues, test-author re-run for oracle issues.”
Two of those three destinations had been removed by earlier architectural work before the router was built. That was not a discovery during this work; the architecture changes were known. The original router design was written against the earlier architecture and had to be redrawn. The post that named the old destinations had been describing a pipeline that no longer existed.

There is no runtime Planner stage to re-decompose against. The Planner still exists, but as an authoring-time concern: it writes decisions, the Synthesizer populates facts at runtime. The 248-runs post is explicit about this: it retired the in-pipeline Planner LLM stage entirely, leaving the Brain layer authored upstream and the runtime pipeline running deterministic synthesis over its output. So re-synthesizing a sub-ticket from the same structured input produces a byte-identical manifest. There is no runtime stage the router could hand a re-decomposition task to in the shipped pipeline. Re-planning against today’s runtime is a no-op; an automated path that authors a corrected ticket mid-loop and re-runs synthesis is planned, but it is one of the destinations the test re-materializer covered later in the post will unlock.
There is no test-author to re-run. The test is rendered by a deterministic materializer from the ticket’s structured test plan, the change covered in the four-eras post that retired the Test Writer and Test Updater LLM stages. A wrong test is not a stage that produced a wrong file; it is wrong materializer inputs. The materializer never reads a corrective brief, so there is nothing to hand one to.
So three of the four non-code diagnoses, the wrong manifest, the wrong test, and the wrong ticket, plus the failed pre-Coder operation, all reduce to the same underlying condition: the upstream specification is insufficient, and no stage downstream of the operator can author a correct one. They converge today on a single operator-facing surface. The router’s job for these in the shipped pipeline is not to repair them automatically yet; that automation is planned but blocked on infrastructure described below. For now its job is to stop wasting a Coder budget on them and surface a structured correction request that names exactly which input is wrong and what machine fact contradicts it.
This is the honest version of the design as it stands today. The original drawing had five repair stages; the shipped pipeline has two automated destinations, the Coder and an operator correction surface. So for now, the inner-loop router’s value is mostly in routing failures away from the Coder when the Coder cannot help, rather than in finding them a new automated home.
Why a deterministic check sits in front of the LLM verdict
Routing a real code bug to the wrong-test path would be worse than doing nothing: it would weaken a correct test to make wrong code pass. So the classification cannot rest on the Debugger’s say-so alone.
Before the wrong-test route fires, a deterministic check re-derives the contradiction from machine-extracted type signatures. When no machine fact is available to confirm the contradiction, the check abstains and the Debugger falls back to the plain code-fix path, which is exactly today’s baseline. A gap in coverage costs a missed routing opportunity, never a wrong repair. The LLM’s classification is a confirmation, not the deciding vote.
This follows the Data Path Principle: a decision that is mechanically computable from machine-extracted facts should be computed, not surfaced to the model with a request to apply the rule. The blind spots in the language server’s analysis are false negatives. They hide facts that exist; they do not invent facts that do not. So a missing fact makes the check abstain, never misfire. That property is what lets this route ship before the language server’s coverage is complete: a gap costs the router a legitimate firing, never a wrong repair.
The outer loop: four of six gates now route to a repair attempt
The end-of-ticket gates are where the router delivers the most operator value, because before it, every one of these failures meant a terminated run and a manual session to recover. The 248-runs post described this exact wiring as still in flux. It has since landed for four of the six gates.
When the language server type-check, the linter, the build step, or the Impl Reviewer rejects the cumulative diff, the router now builds a code-only repair task from that gate’s specific complaints, the failing files and the blockers as constraints, runs one Coder repair pass against it, and re-runs the gate authoritatively. The Impl Reviewer case re-reviews after the repair rather than trusting that the repair satisfied the original objection.
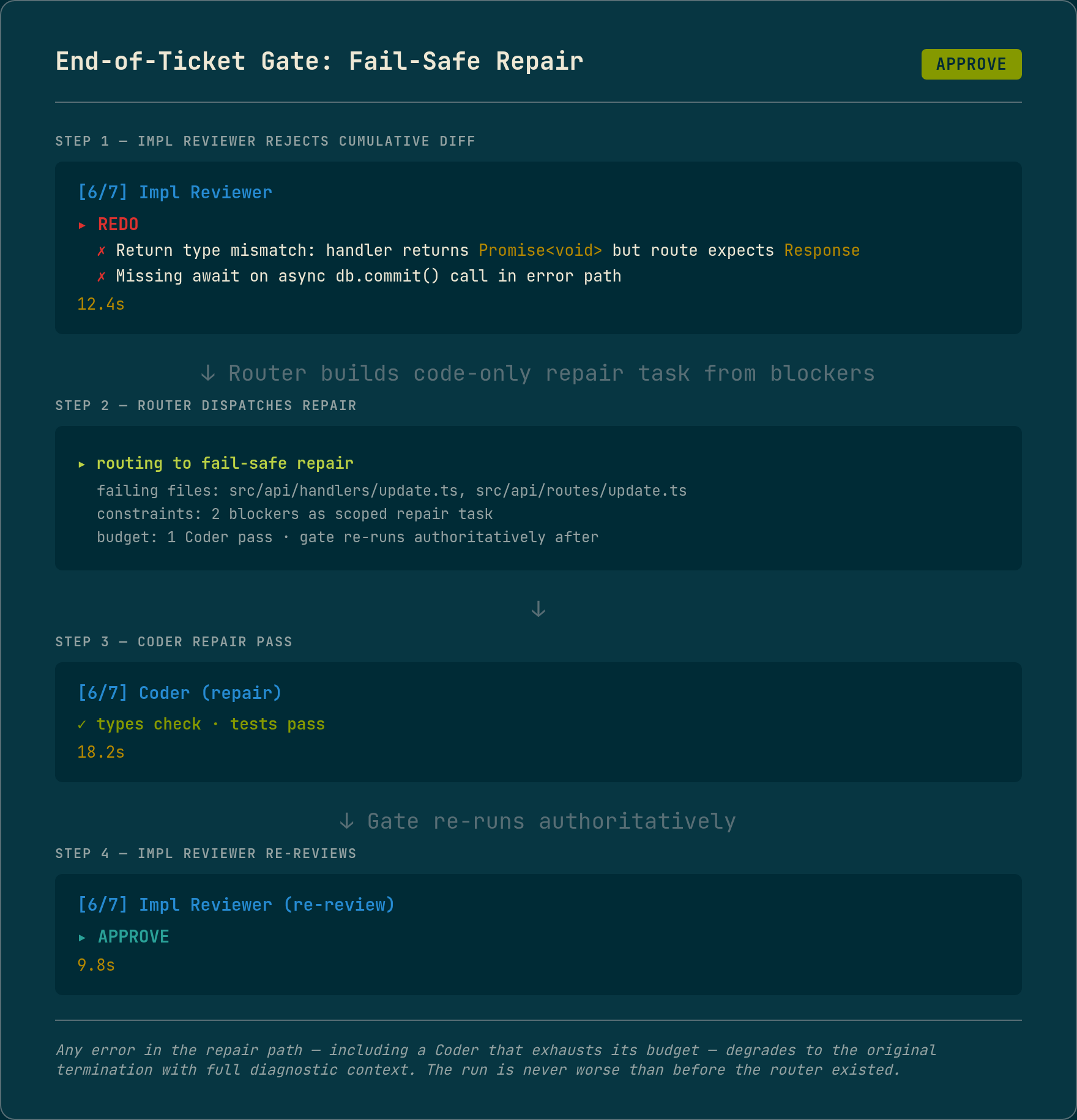
The load-bearing property is that the repair is fail-safe. Any error anywhere in the repair path, including a Coder that exhausts its budget on the repair, degrades to the original termination with full diagnostic context, and one attempt per gate is the hard bound on cost. The hot end-of-ticket path is never worse than it was before the router existed. The router is a strict improvement on terminate-and-halt or it is terminate-and-halt; there is no path where it makes a passing run fail.
The two gates that still terminate are the Test Reviewer and the test-coverage gate. Both want the same destination: a corrected test plan, re-materialized. That destination does not exist yet, which brings us to the limit.
What is still missing, stated plainly
The single largest piece of unbuilt infrastructure behind this router is a way to re-materialize a test mid-loop from a corrected test plan. Every automated repair the router cannot yet do traces back to it: automatically correcting a wrong test and re-rendering it, automatically regenerating a wrong ticket, and the two outer-loop gates that still terminate. Until that piece exists, those failures surface to the operator with a structured correction request instead of repairing themselves. That is a deliberate stopgap, not a finished state.
There is a deliberate line held here, and it is worth naming because it is tempting to cross. No LLM rewrites a rendered test, even as a fallback. The test is the oracle the implementation is validated against, and its trustworthiness comes entirely from being derived deterministically from the spec. An LLM that edits the rendered test can make a wrong oracle pass wrong code, and the Reviewer is only an LLM checking an LLM, which is strictly weaker. The model may propose a corrected structured test plan, which the deterministic pipeline then gates and renders. It never authors the oracle directly. The behavioral oracle describes how that derivation works for a feature class the route suite cannot reach.
And the honest scope caveat: every route is covered by unit tests that exercise its failure case and assert the destination, but only some of them have been observed firing on real runs so far, not all. The Debugger fires on a small tail of tickets, and a given route only gets exercised when a real failure of that exact type comes up, so the rarer routes have not been triggered end to end yet. So this post describes the architecture that shipped and the design reckoning it required, and it is honest about which routes have been seen working versus which have only been proven in tests. It does not yet report how often each route fires correctly across many real failures, because that data does not exist. The empirical question, how accurate the routing is at volume and whether routed repair beats terminate-and-restart on wall time and cost, is the next post, after enough runs exercise every route.
The cost argument has inverted
The original case for this router was savings: stop burning Coder budget on failures the Coder cannot fix. That framing is now mostly wrong, and the reason is itself a result worth stating. On the common path, a ticket reaches completion with zero Coder LLM cycles, because the deterministic floor under the Coder has risen far enough that many tickets never invoke it. The cost on that path is driven by ticket-generation and Reviewer calls rather than code generation, roughly $0.30 in a representative recent run on the ~100k line TypeScript monorepo. The Debugger never fires there. There is no budget to save.
The Debugger fires on a small tail of tickets, under ten percent, down from roughly thirty before the upstream feasibility work. The router does not make the common case cheaper. It changes the rare case from fatal-and-opaque to either non-fatal or cleanly surfaced for operator action, depending on which destination is currently built. On that tail, the entire cost is the wrong-sink waste: a misrouted failure burns a full Coder budget against an unsolvable problem and then terminates anyway, or worse, an end-of-ticket gate failure costs the operator a whole manual recovery session. The router’s return is concentrated in incidents that are few in number but high in per-incident cost and operator time. That is an operator’s framing of the value, not a per-ticket-savings one, and it is the more honest one.
What this is, as a piece of judgment
Stripped to its decision, the router is a bet about which failures are worth automating a repair for and which are better surfaced to a human. The default stays hard-fail: when no destination is clearly correct, terminating with full context is safer than guessing at a repair. A route earns its place only when its destination actually exists and the failure mode of taking it wrongly degrades to the old baseline rather than to something worse. That test is why the inner-loop routes mostly surface to the operator instead of inventing automated repairs, why a deterministic check guards the one route that could weaken a test, and why every outer-loop repair is wrapped so it can only improve on termination.
The earlier post said the Debugger’s narrowness was what made it reliable. The router does not widen the Debugger’s reach into the code. It widens the set of stages the Debugger can hand a verdict to, while keeping each handoff inside a boundary where being wrong costs nothing new. That is the same discipline, applied one level up.
The pipeline runs inside Docker on real tickets against a ~100k line TypeScript monorepo. It is still R&D. This is an update to an earlier, substantially different sketch of the router, not the final account of it. The router described here is wired and unit-tested; some routes have been observed firing on real runs and others have not yet, it has not been measured at volume, and the test re-materialization path it depends on for full automated repair is not built. The final post, with numbers for routing accuracy from real runs, will follow once those pieces land.