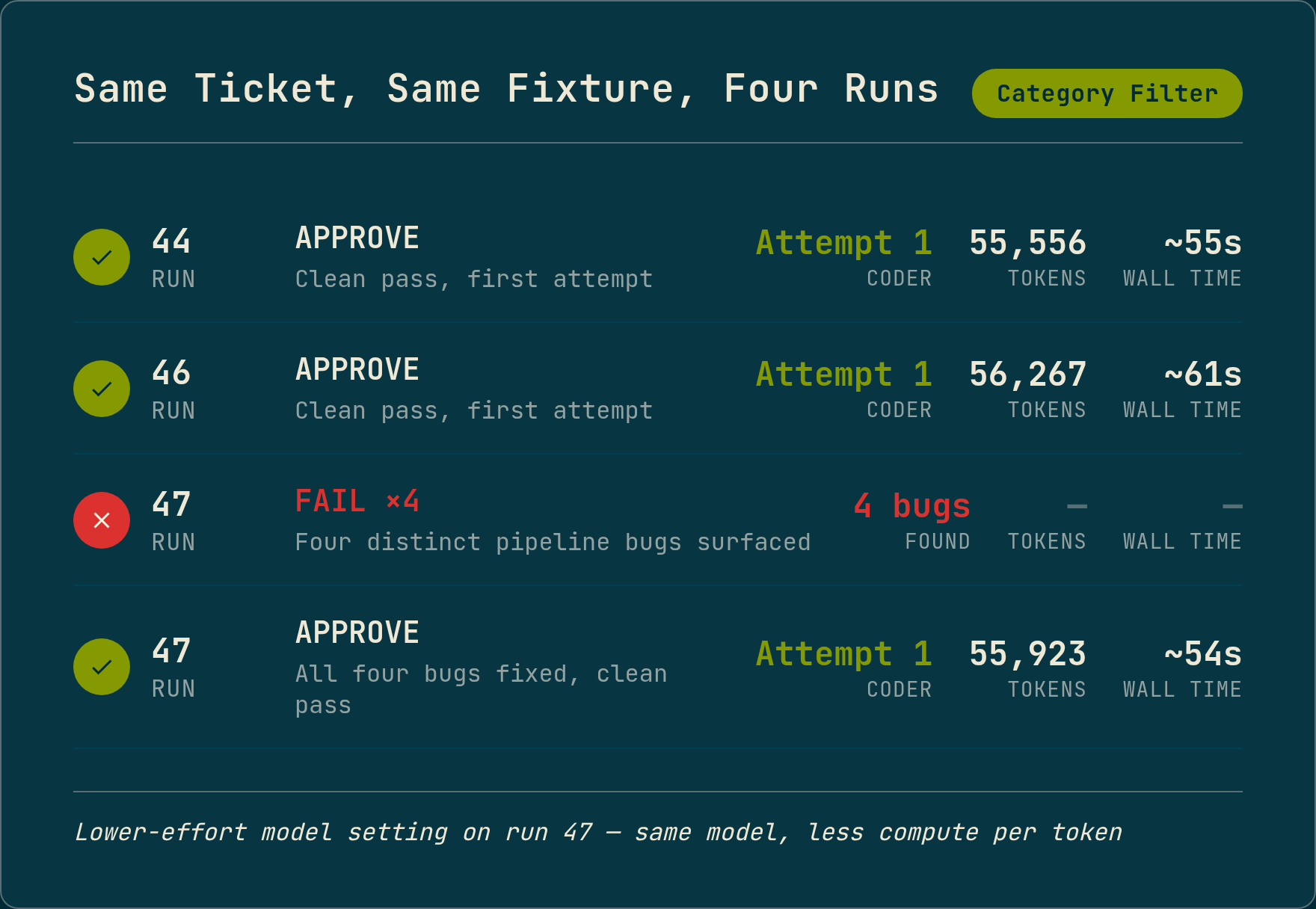
A ticket that had passed cleanly twice before failed four times in a row. Same ticket, same fixture, same pipeline, and the same model, just told to spend less compute per token: only the effort setting changed.
Each failure was a different pipeline bug. All four had existed during the previous runs. The higher-effort setting had worked around every one of them.
The setup
The pipeline runs five agents in sequence: Planner, Test Writer, Coder, Debugger, Reviewer. Each agent runs in its own isolated session with no shared state.
The ticket was a category filter on a blog API endpoint. It had passed twice before, producing clean one-attempt approvals in about 55 seconds. On the third run, the same ticket hit four distinct failures across four consecutive attempts.
Failure 1: constraint in the wrong location
The Test Writer produced CommonJS require() statements in a project that uses ESM imports. The pipeline had a constraint saying “use ESM imports” injected into the prompt. The higher-effort run had followed the constraint anyway, inferring intent from the surrounding context. At lower effort, the model ignored it.
Moving the same constraint to a more prominent position in the prompt was the correction; the model follows it regardless of effort level. Same words, different position. Invisible in a diff.
This is the hardest class to find. The constraint exists, the tests pass at higher effort, and nothing in the output tells you the model is compensating for poor placement. It only surfaces when the model stops compensating.
Failure 2: no recovery for unexpected output format
The Debugger stage returned XML markup instead of JSON. The output parser got an empty string and crashed. The error handler fired a cleanup routine with a misleading message about leftover files when it was actually cleaning up the current run’s output.
The higher-effort run had never produced XML output, so the parser had never been tested on it.
Constraining the Debugger’s output format, adding defensive parsing for unexpected markup, and making the cleanup message report the actual cause rather than assuming one closed it.
Failure 3: missing context
The Coder failed all three attempts on the same test. The implementation needed a pagination utility that existed in the codebase but was not in the Coder’s context. The higher-effort run had inferred the import by reasoning about the surrounding code. At lower effort, the Coder tried to reimplement pagination from scratch and got the edge case wrong every time.
Making the context explicit was the answer. The utility belonged in the Coder’s input, not in the model’s ability to discover it. Every time the pipeline relies on the model “figuring out” something that could be stated directly, that is a structural gap waiting for a weaker run to expose it.
Failure 4: insufficient error feedback
The Test Writer produced a syntax error. The retry mechanism fired, but it sent back a generic “syntax error, try again” with no details. The higher-effort run had never produced a syntax error at this stage, so the retry path had never been exercised with real data.
Including the actual test runner output in the retry message closed it.

The principle
On a previous project, I tested on the oldest, weakest phone with the highest usage share in the analytics. If the app ran smoothly on that device, it ran smoothly on everything newer. You test on the floor, not the ceiling, because the floor is where the structural problems live.
The same applies to AI pipelines. A pipeline that only works because the model is smart enough to fill in what you forgot to specify is not a robust pipeline. The correctness should live in the structure, not in the model’s ability to recover from your gaps.
The lower-effort setting exposed bugs that had already existed at higher effort. Each fix made the pipeline more reliable at every effort level, including the one that had been passing all along.

If your pipeline only shows clean runs at high effort, you do not know where the real guardrails are.
Numbers are from real runs against a TypeScript blog API fixture. The pipeline runs inside Docker with no human in the loop between ticket input and reviewed, committed code.