What happened
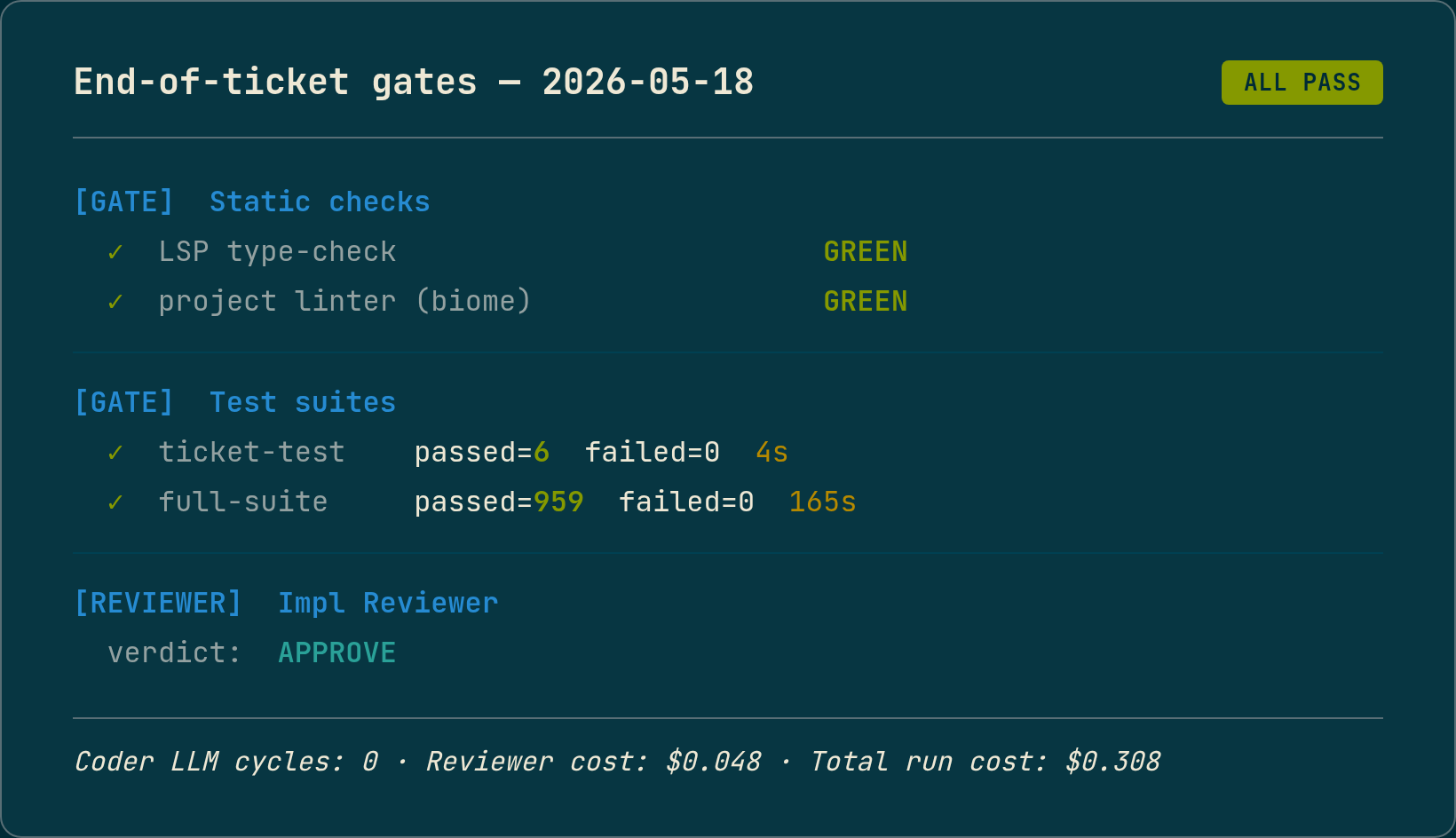
The autonomous engineering pipeline I am building landed its first end-to-end success on a real feature ticket with zero LLM calls authoring source code. Four sub-tickets committed, the ticket-specific test suite passed 6 of 6 cases, the full target test suite passed 959 of 959 cases, and a final semantic reviewer approved the diff. The only two LLM invocations across the entire loop run were the two verification reviewers (one over the test plan, one over the final diff). They cost $0.048 combined.
The cost of source-code authoring LLM calls was $0.
This is a new posture for the pipeline. Previous green runs on similarly shaped tickets paid for at least one Coder LLM cycle, because some part of the behavioural change (a guard placement, a destructure expression, a conditional spread) was being written by the Coder agent in line-level free-form. The Coder no longer fires on this ticket shape, because every line of the committed diff came from a deterministic op handler operating against machine-extracted facts from the registry and abstract syntax tree (AST) walks via Tree-Sitter.
The pipeline still has LLM stages. Before the loop ran, the grounding chat turned operator design decisions into the structured handoff the downstream stages read as ground truth. In the loop itself, the Planner decomposed the ticket into sub-tickets and two Reviewers verified the test plan and the final diff against the acceptance criteria. None of those stages authored a line of source code in this run. The line-level decisions all fell out of structurally-derived data.
This post explains what made that possible, what it doesn’t yet mean, and why the trajectory is specifically a continuation of the four-eras post and the Lego Instructions Principle rather than a novel claim.
The numbers
| Metric | Previous attempt on this ticket (2026-05-14) | This run (2026-05-18) |
|---|---|---|
| Result | Ticket test failed, 5/6 cases | Ticket test passed, 6/6 cases |
| Full target suite | 958/959 | 959/959 |
| Impl Reviewer reached? | No (gated on tests green) | Yes, APPROVE |
| Coder LLM cycles | 1 (one sub-ticket body change) | 0 |
| LLM wall time in the loop | 34 seconds | 11 seconds |
| Total cost (chat + ticket-gen + loop) | $0.681 | $0.308 |
The cost halved. The result strictly improved. The wall time of the loop went up marginally because the new run cleared every gate including the Impl Reviewer that the previous run never reached. Net throughput of “did the work, verified the work, finished green” is faster.
The ticket itself is a small feature add: an optional dryRun flag on a POST /api/items/actions endpoint. When the flag is set, the function short-circuits before any side-effecting call and returns the pre-mutation record. The work threads through four layers of a real production codebase: a Zod discriminated union (three variants), a TypeScript type alias used as an options bag, a 140-line function with branching dispatch over the action discriminator, and an Express-style route handler that builds an options object via conditional spreads.
The work is structurally similar to the threading-ticket shape described in the four-eras post, but the codebase, the feature, and the run series are different. It took seven runs to reach green, all within a single day’s iteration.
What the four sub-tickets actually did
The Planner decomposed the ticket into four sub-tickets. Each one ran with the Coder skipped because two conditions held: the deterministic ops covered the declared work, and the language server reported a clean type-check on the result. Concretely:
Sub-ticket 1. A type-extension op added dryRun?: boolean to the existing options-bag type alias. Its inputs are a target symbol from the registry, a field name and field type from the operator’s structured handoff (the grounding chat output), and the set of regions in the target file that must not be touched. It runs a deterministic Tree-Sitter walk to find the target declaration, inserts the new property, and re-parses to validate. No LLM call.
Sub-ticket 2 (schema-extension). A schema-extension op added dryRun: z.boolean().optional() to every variant of the Zod discriminated union. Its payload carries a list of variant tags, and the driver applies each insert without disturbing adjacent positions in the source, then re-parses once at the end. The variant list itself was populated by an auto-expand populator that walks the Zod source via Tree-Sitter, machine-extracts the discriminator field and variant tags, and stamps them onto the op when the operator did not explicitly scope. No LLM call.
Sub-ticket 3 (body short-circuit). Two ops fired against the dispatch function. The first was an idempotent signature-extension op that checked whether the function’s signature already accepted the field (via a registry-driven type-declaration check against the options-bag type alias). It did, so the op was a no-op. The second was a branch-aware short-circuit op that identified each branch of the dispatch function, walked each branch for the first call to a side-effecting callee (the side-effecting set was machine-extracted from the registry’s caller graph plus the test plan’s mocked-symbols set), and inserted an early-return guard immediately before each. The guard’s return expression was derived from the function’s happy-path return shape, with any out-of-scope identifiers resolved against in-scope equivalents. No LLM call.
Sub-ticket 4 (threading). A call-site threading op read the route handler’s parsed-body shape from the now-extended schema (top-level placement, machine-derived from the Zod AST), prepended an unconditional const { dryRun } = parsedBody; destructure to the handler body, and inserted a conditional-spread entry ...(dryRun !== undefined ? { dryRun } : {}) into the existing executionOptions object literal. Both edits were placed by AST walkers operating on machine-extracted facts. No LLM call.
The diff is structurally trivial when you describe each piece, but every piece had to exist as a deterministic op for the Coder to be skippable. Each one took multiple iterative rounds of architectural work to land.

Why this is a continuation, not a new claim
The four-eras post documented a different ticket’s trajectory across a long stretch of architectural work. That trajectory had four eras: a wiring-patcher era that stopped asking the Coder to write structurally-repeated edits, a deterministic-materializer era that retired the Test Writer and Test Updater LLM stages for test rendering, a validator-and-transformer era that gated test-plan correctness against the call graph, and a discriminating-coverage era that landed cross-scenario assertion coverage. The end state was 9 of 9 tests at $0.074 per test, with the Coder still firing for the actual code-authoring step.
This post is the next state. The Data Path Principle, the Lego Instructions Principle, and the Brain layer / builders boundary have been progressively pushed to the point where the builder layer for source-code authoring is degenerate on this shape.
The seven runs this round followed a recurring pattern. Each one surfaced one structural bug at a different layer of the pipeline. Each fix removed an entire class of downstream LLM fallback rather than tuning a prompt rule. The first run failed because an op’s payload used the wrong field type for one of its inputs; the fix made the correct type machine-selectable so future ops cannot repeat the mismatch. The second failed because a driver’s idempotence check was operating on unparsed text; the fix grounded it against the AST and the registry. The third failed because the op targeted one schema variant when the ticket described three; the fix extended the op to accept multiple targets and added a populator that fills the full list in from the schema automatically. The fourth, fifth, and sixth runs surfaced three more layers (a scope-narrowing step from one op leaking into an unrelated op’s schema lookup, route-path normalisation skipped at a registry lookup, a destructure scope resolved against the wrong narrowed chain). The seventh ran green.
Each of those structural fixes is now part of the pipeline. The next ticket of this shape should land green on the first run, not the seventh.
What stayed LLM
The pipeline is not LLM-free. Three stages ran as LLM invocations across this ticket. The grounding chat ran pre-autonomously: the operator answered structured design questions, the LLM proposed answers grounded against the registry, and the operator confirmed. Its output was the structured handoff the loop read as ground truth. In the autonomous loop itself:
The Planner authored the test plan and the sub-ticket decomposition. It makes shape decisions rather than line-level decisions. The Planner remains LLM-authored because its job is genuinely an interpretive read of the ticket and the codebase.
The two Reviewers (Test Reviewer over the test plan, Impl Reviewer over the final diff) ran one verification pass each. These are verification stages, not authoring stages. Their job is the question that LLMs are genuinely good at: “does this test plan match the acceptance criteria” and “does this diff implement the intent.” Combined cost $0.048. They will probably stay LLM-authored permanently, because rule engines cannot answer semantic-fit questions and the cost is small.
The Coder, the Debugger, and the Test Updater are not retired from the pipeline. They remain present and will fire on tickets where the structural floor is lower. None of them fired in this run.
What this run doesn’t yet mean
The trajectory has not generalised across ticket shapes (a follow-up post has since generalised it to six). The pipeline reached zero-Coder-cycles on one well-shaped ticket. The same ticket shape is overrepresented in my testing because it is structurally the most demanding shape I have so far identified (multi-layer threading across a Zod union, a TypeScript options bag, a branching dispatch function, and a route handler). It is not the only shape.
A ticket that needs a new algorithm, a non-Zod schema, a non-Express framework, or a behavioural change without a corresponding op handler will fire the Coder. The pipeline will be back to iterative gap-filing for that shape. The “seven iterations on one ticket shape, then zero iterations forever” trajectory is not free; it is earned per shape.
The deterministic materializer still produces duplicate scenarios. The materialised test file in this run contains six test cases, two of which are functional duplicates of two others (same action, same dryRun value, same assertions, different prose labels). The test runs green, but the duplication is real. The fix is a scenario-dedup pass upstream of the materializer. That work is filed but not done.
One op-driven sub-ticket emitted an unreachable guard. The body short-circuit op enumerates each return-terminated branch independently and places a guard per branch. In one case (the implicit demo-mode branch inside one of the dispatch function’s default flows), an earlier branch’s guard already short-circuits before the demo-mode block is reached, so the demo-mode block’s guard is dead code at runtime. The driver’s algorithm is structurally correct (each branch is independently guarded against its first side-effecting call) but it produces a redundant emission that a pass detecting guards made unreachable by earlier guards in the same function would catch. That work is also filed but not done. It is harmless today because the redundant guard’s return value is structurally identical to its dominator’s. It becomes a correctness concern if that return derivation ever goes per-branch rather than per-function.
The pipeline is still R&D. It runs against a ~100k line TypeScript monorepo under Docker with Tree-Sitter and a language server. The trajectory is real but the claim is bounded: one ticket shape, on one project, with the Coder degenerate. Not “the Coder is obsolete.”
What this run is evidence of
The pattern is the relevant claim, not the per-ticket result. Each previous run paid an LLM cost on some behavioural shape and filed an entry in the architecture-gaps document to remove that cost. Each fix removed a class of LLM-authored fallback rather than tuning a prompt rule. The fixes compound, because once a behavioural shape is structuralised it stays structuralised. The result is a slow drift of the structural floor underneath the Coder upward, and the Coder’s responsibilities downward.
That is the same pattern the four-eras post was tracing. The difference is that the four-eras post described it at the level of the Test Writer, Test Updater, and a few of the larger structural ops. This post describes the same pattern reaching the Coder itself, on one ticket shape.
The architecture-gaps document still has open entries. Two of them are quality follow-ups filed during this round: dominator pruning for redundant short-circuit guards, and scenario dedup upstream of the deterministic materializer. Neither blocks today’s tickets; each has a concrete fix shape captured. The pattern of “the structural floor rises, the Coder’s responsibilities shrink, the cost per ticket drops” will continue as those entries are landed. Both closed two days later, along with two structural refinements to the grounding chat, covered in the follow-up post.
What today’s run proves is that the floor has reached, at least for one ticket shape, the point where the LLM’s role is fully intent-level and the implementation falls out of structurally-derived data.
The cost per ticket of this shape is now bounded by the verification reviewers, not the authoring stages.
The pattern only generalises if subsequent ticket shapes follow the same trajectory. The trajectory exists and has converged at least once. That was not true a week ago.
The pipeline runs against a real ~100k line TypeScript monorepo under Docker with Tree-Sitter, a language server, and Vitest. Still R&D.