An earlier post argued that prompt rules are advisory and validators are binding. It made the philosophical case and walked one transcript: the Planner read the rule that named the failure mode, then committed the failure mode anyway, citing the constraint as justification. The fix in that post was a validator. The mechanics of that validator stayed at sketch level.
This post is the mechanics. A binding validator in an AI coding agent pipeline has three properties, and any one of them missing turns the validator back into a soft check. The three are: it fires synchronously and pre-commit; the rejection it emits is structured, not prose; and the rejection folds into the offending stage’s retry context as bound input, not as advice.

Synchronous, pre-commit
A binding validator runs before the output it is checking can be acted on by anything downstream. For a manifest, that means before the Coder is dispatched. For a Coder write, that means before any byte hits disk. The schedule is synchronous: the calling stage waits for the verdict, and the verdict is binary.
The contrast is the version where a validator runs asynchronously after the action and surfaces a warning. That version cannot bind. By the time the warning arrives, the action has already been taken. An earlier post on warnings versus hard stops covers what goes wrong when a soft warning sits in the place a binding check should sit. The pipeline learns to ignore it; the next ticket compounds the damage.
Pre-commit also means the validator runs against the proposed action, not against the world after the action. The write gate checks the file path the Coder asked to write, not the file that ended up on disk, because the goal is to prevent the write, not to detect it after the fact. A post-write check that reverts is a different design with different failure modes: half-applied state, partial rollbacks, divergence between the registry and disk. Pre-commit avoids that whole class.
Structured errors
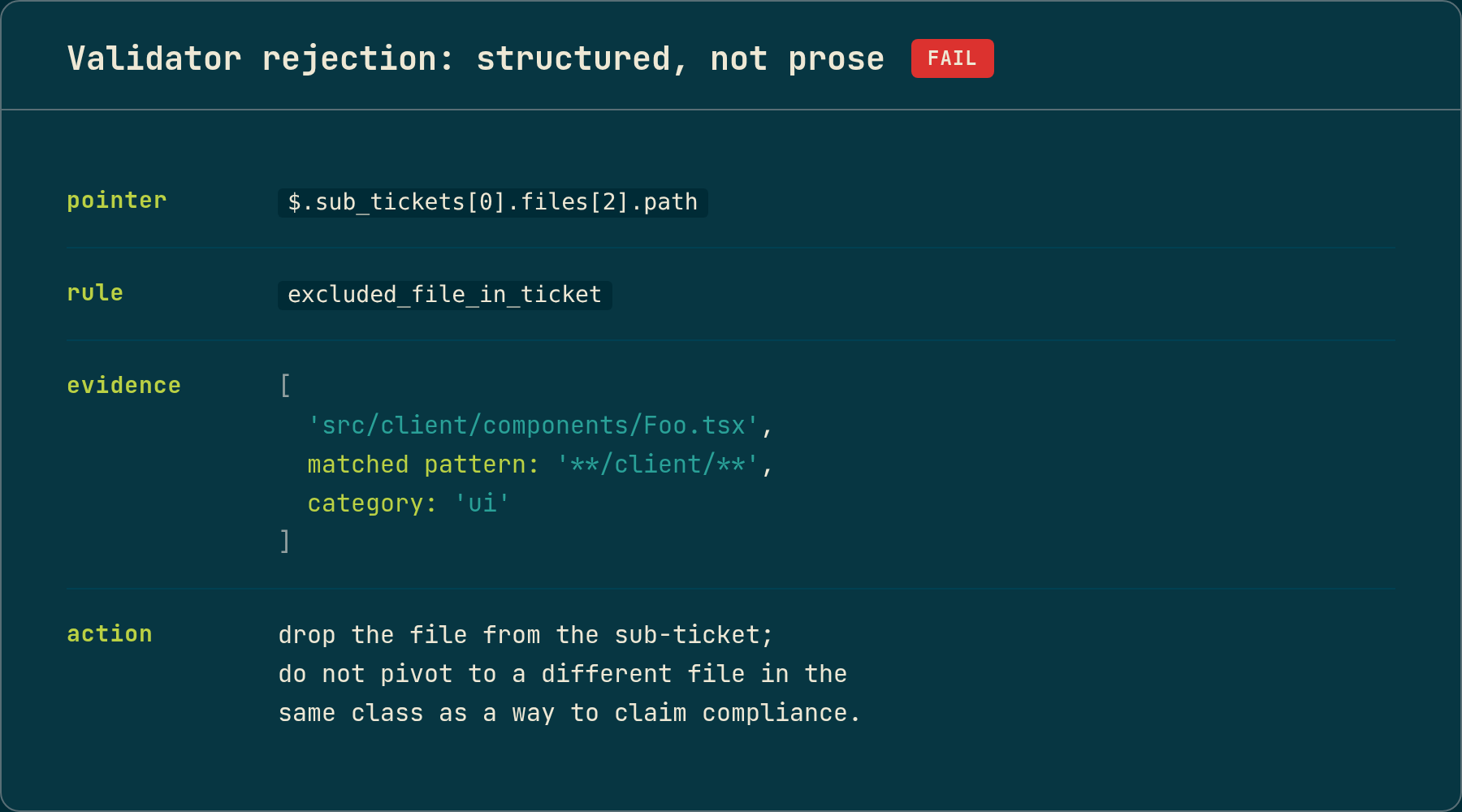
A validator’s rejection is data, not prose. The minimum useful structure is four fields:
- A pointer to the offending field in the upstream output. Not “your manifest is wrong,” but the precise path of the specific field whose value triggered the rule.
- The rule that fired. Named, not described. A symbol the calling stage can check against without parsing English.
- The evidence. The literal value that triggered the rule, plus whatever context made it triggerable: a glob pattern, a registry record, a language-server result.
- The corrective action. Specifically scoped: drop this field, replace this path, re-emit this sub-ticket. Not “please reconsider.”
The advisory-and-binding post showed one such payload: a path, a matched pattern, the excluded category, and a corrective action telling the Planner exactly what to drop and what not to pivot to. That shape is load-bearing. The Planner’s retry call cannot productively act on “your manifest violated a rule.” It can act on “the file at sub_tickets[0].files[2].path matches the excluded-category pattern; drop the file, do not pivot to a different file in the same class.”
Structured rejections also compose. When two validators reject the same emission, the calling stage receives a list of rejections, each pointing at its own field. The retry then retries against the union, not against whichever rejection happened to land in stderr last. A prose error cannot compose like that without a parser, and the parser is the structured-error schema by another name.
Retry folding
A rejection lands in the retry context as bound input. The next attempt does not see the rejection as advice from a reviewer; it sees the validator’s structured payload at the same precedence as the original ticket and the registry-supplied facts. The phrasing in the retry prompt is “the previous attempt was rejected with this evidence; emit the next attempt accounting for this,” not “consider the following critique.”
The framing matters for the same reason the predecessor post named: the model has a strong learned pattern for treating critique as advisory. Calling a structured rejection “feedback” surfaces the prior; treating it as a constraint of equal weight to the ticket suppresses it. The error schema is the constraint surface, and the retry prompt presents it that way.
A persistent validator rejection is the signal that the failure is upstream.
Folding interacts with the pipeline’s retry budget. Each stage has a bounded number of attempts, and a validator-rejected attempt counts against the budget the same as any other failed attempt. A binding validator that cannot eventually be satisfied is by design a budget-burner: the run halts, the rejection surfaces, the workspace resets. The right read on a stuck validator-retry loop is not that the validator is too strict. It is that the upstream stage cannot satisfy the constraint with the input it has, and the fix is upstream of the validator, not at it.
That second part is easy to skip. When the validator keeps rejecting, the design instinct is to relax the rule. The honest read across observed runs is that the rule is fine and the upstream input is bad. Relaxing the rule lets the wrong output through; fixing the upstream input lets the right output through. The retry-budget post covers the routing: a Debugger diagnosis can route a manifest issue back to the Planner instead of staying inside the Coder loop, exactly because some failures are not solvable at the layer they surfaced at.
Where the validators sit
Three places in the current pipeline, each using the same shape:
The pre-Planner feasibility gate runs on the ticket before the Planner is dispatched. It checks that the preconditions resolve against the registry, that every named symbol exists, that every authorized file is on disk, that every operation the Coder is asked to perform targets a real type. A failure halts the run with a structured diagnosis and saves the LLM call entirely. This is the validator that costs the least to fire because it has no model call sitting upstream of it.
The manifest validator runs on the Planner’s output before any builder fires. The most consequential check today is the user-excluded-categories one from the advisory-and-binding post: paths in the manifest are matched against patterns derived from the user’s prose by a separate pre-extraction stage. A rejection folds into the Planner’s one-shot re-plan budget as the structured payload above. When the Planner exhausts the re-plan, the run halts.
The write gate runs on every Coder-attempted write before the bytes reach disk. It checks the file path against the manifest’s authorized list and rejects out-of-scope writes. The BLOG-010 incident walks one of those rejections end to end: the Coder reasoned its way to a correct fix that required writing a file outside the manifest, and the gate stopped the write before the workspace was corrupted.
The placement and the rule differ; the wiring does not.
Why this is worth describing
The advisory-and-binding post made one architectural argument: when the model has a strong prior, name the constraint as data and validate the output. The mechanics matter because each of the three properties is individually load-bearing.
When a validator is asynchronous, the action has already happened. When the rejection is prose, the retry argues with the message rather than correcting the field. When there is no retry folding, the next attempt repeats the same mistake because the rejection was never bound as input. A validator that fires after the Coder writes is not the validator the advisory-and-binding post described; it is a logger.
Most “we have validators in our pipeline” claims I have read fail one of these three properties on close inspection, usually the third. The retry context still treats the rejection as commentary, the model still resolves to its prior, and the validator becomes part of the noise the next attempt is trained to politely acknowledge before doing what it was going to do anyway.
The pipeline runs inside Docker on real tickets against a TypeScript fixture and a ~100k line TypeScript monorepo. The pre-Planner gate, the manifest validator, and the write gate are all live. The error schema is shared across them; the rule sets are stage-specific. Still R&D.