What this post is
This is a follow-up to one ticket across four architectural eras, which tracked the same feature ticket through four architectural eras of the autonomous engineering pipeline I am building. That post ended at Era 4, where the pipeline started generating two test cases per threading hop, one for each value of a flag, so a passing run proved the flag was threaded with both values rather than hardcoded. This post is the next step, and it closes a gap that Era 4’s bivalent cases did not.
The gap is specific. The ticket adds an optional flag that, when set, skips an expensive downstream call inside a business-logic function. Era 4 proved the flag reaches the boundary. It did not, and structurally could not, prove that setting the flag actually changes what the function does. On this codebase a green run can ship with the feature completely broken, and once it did. This post is about test generation that catches that instead: deriving a behavioral test from the implementation rather than asking the LLM to write one, committing it, gating the run on it, and proving it is not vacuous with mutation testing.
The bug that passed every gate
The feature is a guard. Inside a function in the pipeline module, call it processItem, an expensive call to enrichItem is wrapped so that when the request sets the skip flag, enrichItem does not run. Three other calls in the same function, selectTargets, resolveSettings, and extractMetadata, must still run regardless of the flag. The operator’s design was explicit about that second half: skip the enrichment only, keep everything else.
In an earlier run, the implementation got the first half right and the second half wrong. With the flag set it skipped enrichItem, and it also skipped one of the calls that was supposed to keep running. The test suite passed. Both Reviewers, the Test Reviewer that checks test correctness and the Impl Reviewer that checks implementation correctness, approved. The run reported full completion. The only reason the bug did not ship was that I compared the committed code against the design and noticed the divergence.
That is a process failure, not a code failure. The route test suite was that gate, and the reason it could not see the bug is structural.
A gate that passes on a broken feature is worse than no gate, because it converts “we have not checked this” into “we checked this and it is fine.”
Why the route test is structurally blind
Every route test in this project starts by mocking the entire pipeline module. The test helper that boots the server calls vi.mock("@server/index", ...) and replaces all of its named exports, including processItem, with stubs that return a fixed value:
vi.mock('@server/index', () => ({
runPipeline: vi.fn().mockResolvedValue({ ok: true }),
processItem: vi.fn().mockResolvedValue({ ok: true }),
enrichItem: vi.fn().mockResolvedValue({ ok: true }),
// ...the rest of the module, all replaced with stubs
}));This is a deliberate and correct choice. Route tests verify wiring: that a request hits the right handler, parses correctly, and calls the pipeline with the right arguments. Running the real pipeline inside every route test would make the suite slow and would couple HTTP-level tests to deep business logic. So the route tests flat-stub the boundary on purpose.
The consequence is that the real processItem never runs in a route test. Its body, including the guard around enrichItem, is replaced by a stub that returns { ok: true }. A route test can assert that the flag was threaded to the boundary. It cannot assert anything about what the flag does, because the code that acts on the flag does not execute. Delete the guard entirely and every route test stays green, because no route test ever reached the guard.
This is the testing pyramid stated as a constraint rather than a recommendation. Integration tests verify wiring; unit tests verify logic. The feature’s behavior lives below the boundary the integration tests stub, so it is observable only at the unit level, and the pipeline was not generating a unit test for it.

Two claims, two altitudes
The feature makes two claims that are observable at different levels:
- Plumbing. The flag reaches the boundary. Observable at the route. The route test already covers this, and Era 4’s bivalent cases covered both flag values of it.
- Behavior. When the flag is set,
enrichItemis suppressed andselectTargets,resolveSettings, andextractMetadatastill run. Observable only inprocessItem’s own unit test, above the flat-stub, and the pipeline was not generating one.
The behavior claim has two halves of its own. The gating half is that the gated call is suppressed when the flag is set and runs when it is not. The preservation half is that the calls the operator declared must be preserved still run when the flag is set. The bug I caught was a preservation-half bug: the gating worked, a preserved call was dropped. Asserting the gating half alone would not have caught it.
The behavioral oracle: a test derived from the implementation’s own operation
The pipeline does not implement the guard by handing the function to the Coder and asking it to write the branch. It implements it with a structured operation in the manifest, a conditional-skip operation that names the function, the flag, and the call to wrap. That operation drives the deterministic edit that writes the guard. It is also a machine-readable statement of the exact behavior the feature introduces.
So the same operation that writes the implementation is used to derive the test. The pipeline reads the conditional-skip operation, identifies the function as the altitude where the behavior is observable, and generates a second test file: a unit test that imports the real processItem from the un-stubbed module, mocks only the leaf calls it asserts on, and runs the function directly with the flag set and unset.
import { processItem } from '@server/index'; // the real function, not the route stub
import { enrichItem } from '@server/enrich';
import { selectTargets } from '@server/targets';
it('skip set: enrichItem suppressed, selectTargets still runs', async () => {
const rec = await createRecord({
/* seeded by the same setup the route test uses */
});
await processItem(rec.id, { skip: true });
expect(vi.mocked(enrichItem)).not.toHaveBeenCalled(); // gating half
expect(vi.mocked(selectTargets)).toHaveBeenCalledOnce(); // preservation half
});
it('skip unset: enrichItem runs', async () => {
const rec = await createRecord({
/* same setup */
});
await processItem(rec.id, { skip: false });
expect(vi.mocked(enrichItem)).toHaveBeenCalledOnce();
});The two cases differ only by the flag, and the outcome flips with it. That is a bivalent test of the actual behavior, at the altitude where the behavior is visible. No model authored it. It is derived from the same operation that drives the Coder, which is the Data Path Principle applied to test generation: the operation is the single source of truth for both the implementation and the test, so the two cannot drift. The preserved calls come from the operator’s design, captured upstream as the set of calls to preserve, so the preservation half is generated for free from the same intent that drives the guard. The generation is deterministic, so the behavioral coverage costs zero tokens and a few seconds of a vitest run.
From proven to protected: committing and gating the oracle
The first version of this generated the test, ran it, reported a pass-or-fail verdict, and then deleted it. That was deliberate. A new generated test that runs against deep business logic and a real database has a lot of ways to be wrong about its own setup, and a wrong setup looks like a failing test. Running it non-blocking first, where a failure is a log line rather than a broken run, surfaced three real setup bugs in the generator across successive runs without ever red-flagging a correct implementation. Each was fixed before the test was allowed to block anything.
Once the generated test passed cleanly twice in a row, it was committed as a real file and the run was gated on it. The test gets its own confirm-RED: the pipeline runs it before the implementation exists and requires it to fail. A test that has only ever been checked green-after-implementation can be vacuous, passing for a reason unrelated to the behavior. Requiring it to fail first, then pass after the guard is written, proves it exercises the thing it claims to.
The gate placement matters for cost of ownership. The committed behavioral test runs at the unit-test stage, before the full suite. The full suite on this project takes minutes; the single behavioral test takes about three seconds. Gating the run on the fast, scoped test first means a broken guard fails the run in seconds rather than after a full-suite cycle. A failing guard shows up on the behavioral test before the full suite runs; the full suite only runs when the fast gate is green.
Holding generated test code to the same bar, without handing it to the Coder
Committing a generated test file raised a question the transient version never had to answer: who fixes it if it does not type-check. The first committed run failed on it. The generated test referenced a capture type that the test setup uses but did not import it, so the end-of-ticket type-check failed. The pipeline’s repair routing did what it does for any file with a type error: it sent the file to the Coder for a fix. That was a routing logic error. The Coder is not permitted to modify generated files: generated artifacts are owned by the generator, not the Coder, so the run failed with the type error unresolved.
The fix has two parts, and the second is a process boundary, not a code change. First, the generated test now goes through the same language-server and linter autofix passes that every other materialized file already gets, which resolves a missing import by adding it, the same way it does for the route test. Second, a residual diagnostic on a generated file is never routed to the Coder. The Coder owns hand-written code. A type error in a generated artifact is a generator bug, and the run fails it with that attribution rather than spending Coder attempts on a file the Coder does not own.
Mutation testing: proving the oracle is not vacuous
The standard way to check whether a test actually catches the bug it claims to is mutation testing: introduce a small deliberate bug into the source, a mutant, and confirm the test fails. A committed, gated test that can pass on a broken implementation is indistinguishable from one that asserts nothing.
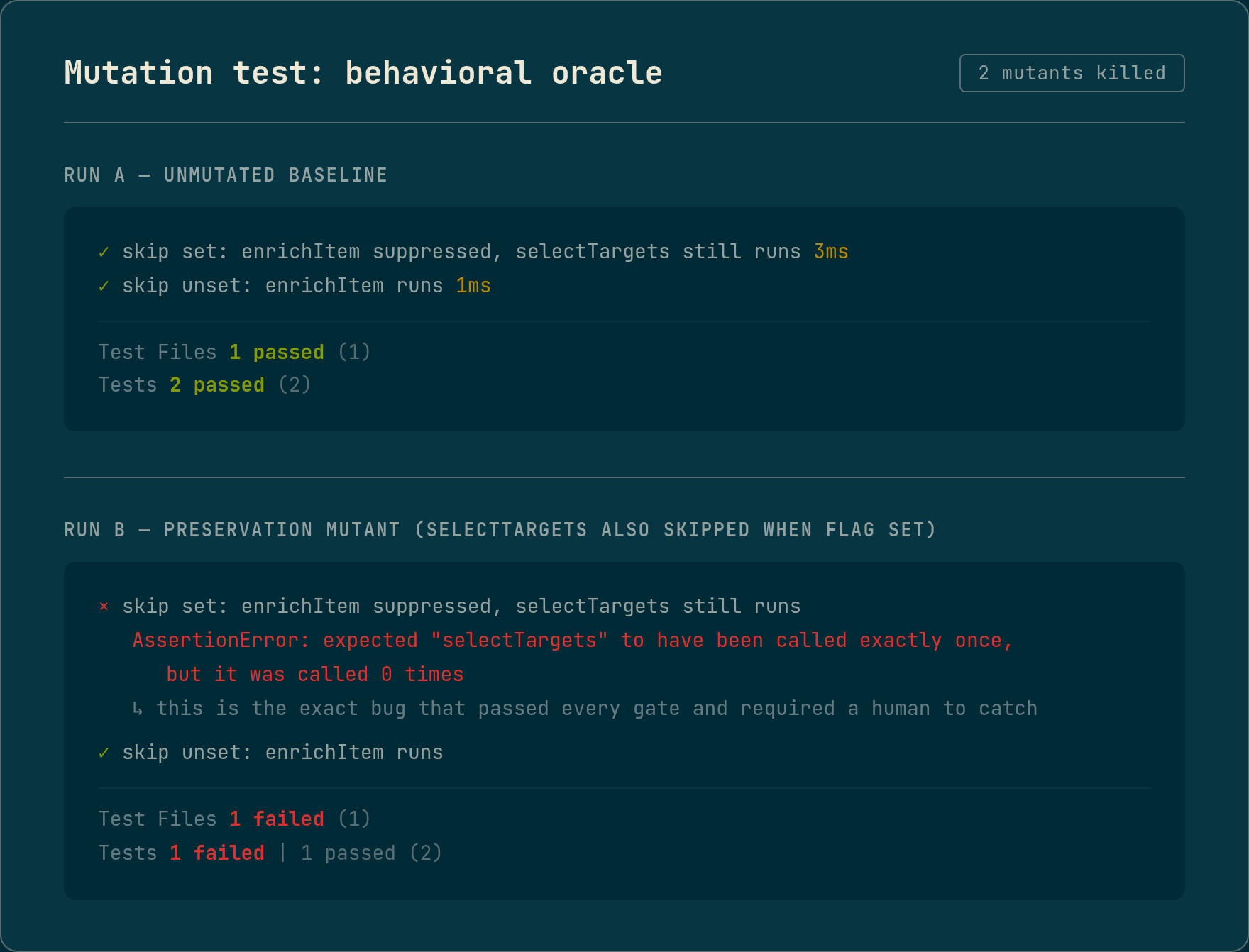
In an isolated copy of the codebase, with the real target left untouched, the committed behavioral test was run against two mutants:
- Gating mutant. Weaken the guard so
enrichItemalways runs regardless of the flag. The behavioral test fails onexpect(enrichItem).not.toHaveBeenCalled(). - Preservation mutant. Skip
selectTargetswhen the flag is set, precisely the bug I caught earlier. The behavioral test fails onexpect(selectTargets).toHaveBeenCalledOnce().
Both mutants are killed: the test goes red on each, and green on the unmutated baseline. The preservation mutant is the one that matters, because it is the precise failure that passed every gate and both Reviewers by hand in the earlier run. It now fails the run on its own, in seconds, with no human in the loop.
confirm-RED is a mutation test that runs on every real run, not just in this manual exercise. The implementation does not exist when the test first runs, which is the no-guard mutant, and the test is required to fail on it. The behavior is checked against a broken baseline every time, by construction.
Since then: observing a stateful write without replacing its module
The version above proves the preservation half on three preserved calls: selectTargets, resolveSettings, and extractMetadata. All three are stateless functions in service modules. The oracle mocks each one and asserts it was called. A later run on the same ticket added a fourth preserved call, and it did not follow that pattern.
The fourth call is updateRecord, a repository write that persists the result the function produces. It is the call that separates “the flag was honored and the record was still saved” from “the flag was honored and the save was silently dropped,” so it is worth asserting. Two things broke when it was added, and both were the kind of bug the rest of this pipeline exists to remove.
The first was ambiguous resolution. updateRecord is defined in two modules. When the oracle tried to resolve which module to spy by name, it found two candidates and dropped the assertion rather than guess. The oracle lost its fourth assertion with a log line and no failure. The fix is the Data Path Principle again: do not re-resolve a fact by name when the structure already holds it. The call graph already records which module owns the call, pinned by symbol identity rather than name, so the spy is derived from structure rather than guessed from string matching.
The second was about observation rather than resolution, and it is the more general lesson. updateRecord lives in the same module the oracle imports its seed helper createRecord from. The oracle’s standard way to make a call observable is to mock its module, which Vitest does by hoisting a vi.mock to the top of the file, before any test runs. That hoist re-evaluates the module before the test harness has reset the module cache and migrated its in-memory database. So createRecord, imported from the same hoisted module, binds to a database with no tables, and the test dies with “no such table” before it asserts anything. The three-callee oracle never hit this, because its preserved calls were in stateless service modules it did not also need a live helper from.
The fix is structural and applies to any function with the same topology. When a module is both mocked and the source of a live helper the test uses, the oracle observes the call in place: it imports the real module after the harness has set up, then spies on the single export it watches, rather than hoisting a whole-module mock. The spy records the call without re-evaluating the module, so the live helper keeps its real, migrated database. The general rule is that whole-module replacement is the wrong tool when you also need a live symbol from that module, or when the module initialises itself against state the test sets up at runtime. The pipeline detects the case from structure alone, the same module serving as both a mock target and a setup-helper source, so no model decides it, and the Vitest spy is one framework’s rendering of a rule another would express as its own in-place patch.

With both fixes the oracle asserts all four preserved calls, the write included, still run when the flag is set. The behavior the post proves is now complete for a preserved call that touches state, not only for the stateless ones it started with.
Cost: behavioral coverage at zero marginal LLM cost
The run that committed and gated the behavioral test cost the same as the runs before it in LLM terms. The only two LLM calls in the run are the two Reviewers; all of the sub-tickets committed through deterministic operations with no Coder call, the zero-Coder mode an earlier post describes. Everything added here is deterministic: deriving the test from the operation, composing its setup, confirm-RED, the autofix passes, and the gate are all non-LLM steps and a vitest run. The behavioral coverage, the preservation half included, adds zero LLM calls and zero tokens over the previous baseline. It is paid for in deterministic code and a few seconds of test time, not in model spend.
What this is not
This is one ticket family on one TypeScript codebase, not a benchmark. The behavior it proves is real, and the mutation test is real, but the generalization claim is narrower than the result might suggest (a follow-up post generalises it to six ticket types).
The setup the generated test uses is now matched per function to a declared setup fixture that actually stands up the modules the function lives under, where which modules a fixture stands up is machine-derived from the prod imports of its own file, static and dynamic, rather than assumed. A function that no fixture covers gets no test rather than a borrowed, unrelated setup, which narrows the distance between “works on this ticket” and “works on any function.” The reach is still bounded by what the project’s fixture catalog can stand up.
The behavioral test enforces the operator’s declared intent. The preservation half exists because the operator declared which calls to preserve and that declaration flowed through to the test. If the intent is not captured upstream, there is nothing for the test to enforce. The enforcement layer is now solid; it sits on top of an intent-capture layer that is a separate concern.
The generated test is held to the type-check and linter bar, it is mutation-proven, and the Test Reviewer now judges each committed oracle the way it judges a hand-written test. The trust still rests first on determinism, the test deriving from the same operation that drives the implementation, with the Reviewer pass as defense in depth on top of that.
The headline is that a bug which passed every gate and required me to catch now fails the run on its own, proven by mutation testing, at zero marginal model cost. The structural point is that the pipeline can now test behavior at the altitude where the behavior is observable, derived from the same operation that writes the behavior, rather than testing only what the route exposes.
The pipeline runs inside Docker against a ~100k line TypeScript monorepo. The runs in this post are from the pipeline’s run archive between 2026-05-30 and 2026-06-02. Still R&D.