What this post is
This is a follow-up to the behavioral oracle, which showed how the pipeline derives a behavioral test from the same structured operation that writes a guard, then commits it, gates on it, and proves it with mutation testing. That post drew one boundary on purpose. The behavioral oracle enforces the operator’s declared intent, and if the intent is not captured correctly upstream, there is nothing for the test to enforce. It called intent capture a separate concern and left it there.
This post is that separate concern. It is about LLM non-determinism at the stage where an AI coding agent turns a sentence of operator prose into a specific symbol the rest of the pipeline acts on. For a while the pipeline made that translation by guessing. This is the story of the guess, a fix for it that passed every unit test and then failed two runs in five in production, what actually worked (which was not a better guess), and the lesson underneath all of it: which decisions a pipeline can make alone, which it cannot, and how easy it is to undo a correct human answer by feeding it back to the model.
The function identity the behavioral oracle takes as given
The feature is the same one from the earlier posts: an optional flag that, when set, skips an expensive call inside a business-logic function. Call the function processItem and the call it skips enrichItem. The behavioral oracle proves that with the flag set, enrichItem is suppressed and the calls the operator wanted preserved, selectTargets and updateRecord, still run.
Every clause of that sentence names a specific function. The pipeline has to know the call to skip is enrichItem and not something else, because that name drives the conditional-skip operation, and the conditional-skip operation drives both the implementation edit and the generated test. Get the function wrong and the pipeline confidently builds, tests, and ships a guard around the wrong call.
The operator does not write enrichItem. The operator writes prose, something close to “let me advance an item to Ready without enriching it.” No function name, a description of a behavior. Turning that description into a symbol the pipeline can act on is the intent-capture step. It is the kind of fuzzy, prose-shaped problem an LLM is good at and deterministic code is not, which is why it was tempting to leave the whole thing to the model, and why that was the wrong instinct.
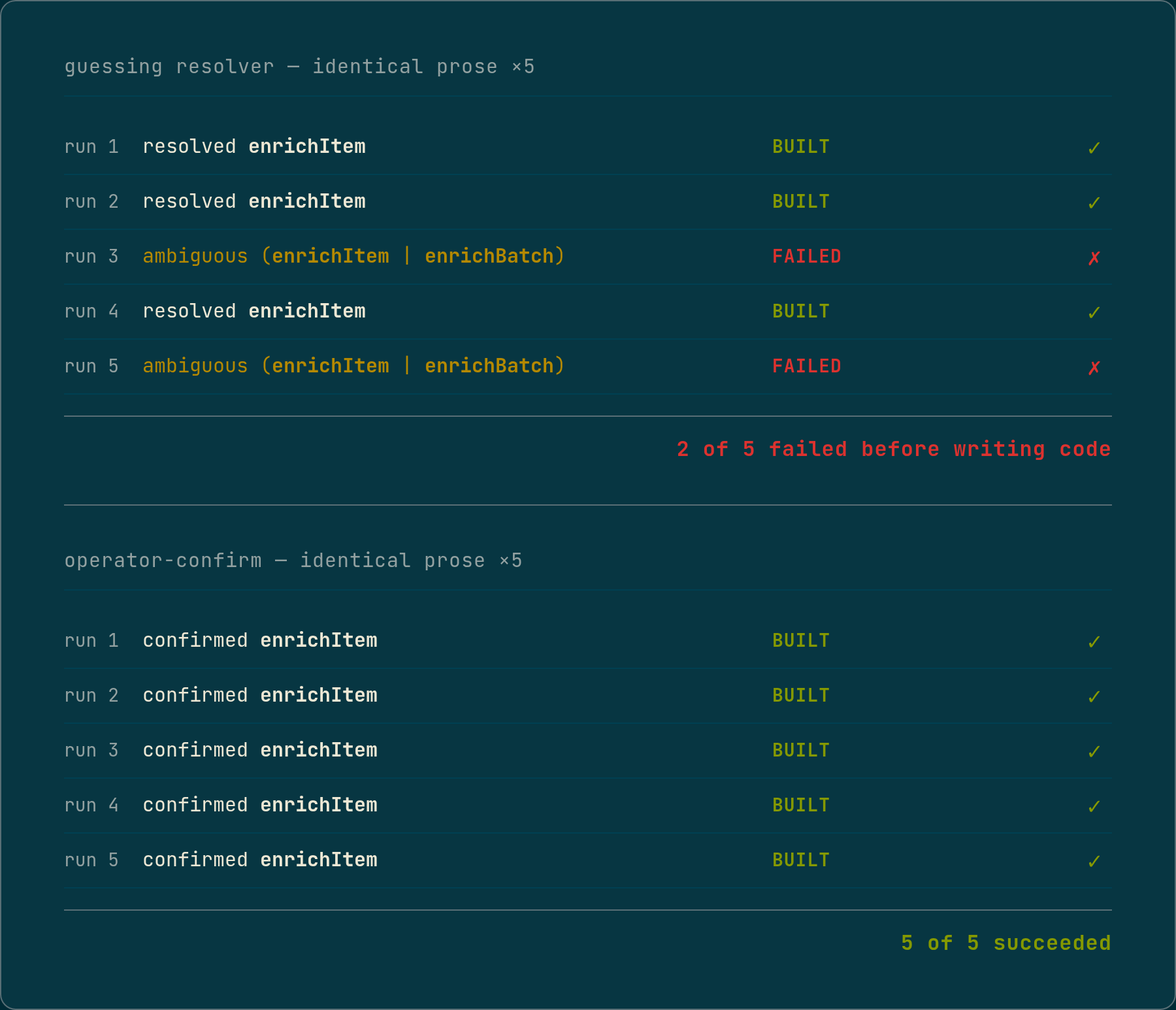
The same sentence resolves to two different functions
The grounding chat reads the prose and extracts a few behavior keywords, lowercase stems pulled from the sentence. A deterministic resolver then ranks the functions reachable from the entry point against those stems and picks the closest match. Run the identical prose twice and the extracted stems come back different. The extraction is an LLM call, and the model pulls a slightly different set of stems out of the same sentence on different runs. The prose is genuinely ambiguous about which words are the key ones, so the model has real latitude, and it uses it.
That would be harmless if the resolver were robust to the variation. It was not. The codebase has two functions a reader could plausibly map the prose onto: enrichItem, the one the operator means, and enrichBatch, a near-twin reachable from the same entry point. On the runs where the extracted stems uniquely favor enrichItem, the resolver picks it cleanly. On the runs where the stems no longer separate the two, the resolver sees two near-equal matches and, correctly, refuses to pick. It returns an ambiguous result, and the run fails before writing a line of code.
On identical prose, one run built the feature and the next failed before writing any code. I measured it on a clean baseline, the same prose and the same answers each time, and two runs in five failed outright. The only thing that varied was the stem set the model happened to emit.
This is the kind of run-to-run variance the Data Path Principle exists to remove, one stage earlier than I had been applying it. I had spent a lot of effort making the stages after the structured handoff deterministic. The handoff itself, the structured capture of operator intent, was still being authored by an LLM, and it wobbled.
Why a smarter resolver cannot break the tie
The first instinct, and the one I reached for, is to make the resolver smarter. The keywords are matching two functions, so a better scoring function should break the tie. Weight the rarer, more specific stem higher. Reduce how much the shared part of the two names counts. Tune the threshold.
This instinct is wrong, and it is worth naming why, because it is the same instinct behind every per-field prompt patch that hits a ceiling. The information needed to choose between enrichItem and enrichBatch is not in the prose. The operator wrote a sentence about enriching an item, and both functions are, by their names, things that enrich. A human who knew the codebase would pick instantly, because the knowledge is in the human, not in the seven words of prose. A resolver that picks confidently here is guessing and hiding the guess, and on this codebase a hidden wrong guess does not fail loudly. It builds the wrong feature, the behavioral oracle tests that wrong feature green against itself, and it ships.
This is the same pattern as a bug from the behavioral-oracle post, one layer up. There, the oracle tried to resolve which of two modules owned a call by name, found two candidates, and the correction was to stop resolving by name and read the ownership the registry already held by structure. Here there is no structural fact to fall back on. The call graph has two real functions, and the prose does not say which one. The fact the resolver needs to choose does not exist anywhere the machine can see it. It exists only in the operator’s knowledge of the codebase.
A fix that passed every test and failed 40% of production runs
I did not learn this cleanly. I learned it by shipping the wrong fix first.
I rewrote the resolver’s scoring to favor the discriminating stem over the shared one. I wrote unit tests for it. They passed. The case I had in mind resolved to enrichItem, the variant with an extra stem also resolved to enrichItem, and the test that a stray stem could not hijack the pick was green. I was satisfied the residual ambiguity was closed.
Then I ran it against the real pipeline five times on a clean baseline, and two of the five runs failed, the exact failure I thought I had fixed. The new scoring put one common variant just inside the ambiguity threshold between enrichItem and enrichBatch. The old scoring had actually handled that variant, and mine had regressed it.
My test fixture was a hand-built list of candidate functions, and it did not include enrichBatch. In the ~100k line TypeScript monorepo, enrichBatch sits in the reachable set a few hops from the entry point. In my fixture it did not exist, so the fixture could not produce the two-function tie that the real call graph produces on every run. The tests were green against a world missing the one function that breaks the feature.
That is the failure I now keep as a standing entry in the failure-modes document. A change to resolver scoring has to be validated against a live-representative candidate set, the actual reachable functions with their actual near-twins, not a fixture built to make the case the author already had in mind. A test suite that is green against a fixture missing the function its target collides with is not evidence the feature works. It is evidence the fixture was incomplete.
The measurement only works on a clean baseline
This was not a precondition I discovered here. The pipeline already enforces it on its own work: before any agent runs, it confirms the target’s baseline is green and stops if it is not, on the principle that an agent started on top of an unconfirmed state is working against the mess rather than the task. I had not held my own measurement harness to the same standard. The five-run measurement is only trustworthy if every run starts from the same clean state, and the pipeline resolves intent against the registry built from the target codebase, so if the target tree is dirty, left modified by a previous run, the reachable function set is wrong and the resolver fails for a reason that has nothing to do with the prose.
My first attempt to measure the failure rate produced noise, because the target fixture was carrying close to a thousand modified files from an earlier session and the entry point resolved to the wrong route entirely. This was not a subtle trap. It is the same mistake the pipeline already refuses to make for the assembly stage, and I made it by hand because I had left the measurement step outside that rule. A dirty tree is not a valid green signal, and a measurement taken on top of one is measuring the dirt.
So the grounding chat now refuses to run on a dirty target tree, the same way the assembly stage refuses an unconfirmed baseline. Before the first LLM call, it checks that the target’s working tree is clean and on its main branch, and if it is not, it stops with an actionable message rather than producing a handoff built on partial state. This is the same posture as preferring a hard stop to a warning. A grounding chat that runs against a dirty fixture produces a confidently-wrong handoff, which is worse than not running, because it converts “we did not check this” into “we checked this and it is fine.” The gate is what made the failure rate real, and it is what let the next measurement catch the regression I had shipped. Without a clean baseline there is no measurement to trust, only noise that happens to look like a failure rate.
Rank the candidates, ask the operator
The real fix follows from naming the problem correctly. Resolving vague prose to one of several real functions is a recall problem, surface the plausible candidates, not a derivation the machine can close on its own. The pipeline already had the right pattern for this, one decision over.
When the operator’s prose matches more than one registered route, the grounding chat does not guess the entry point. It ranks the candidate routes, shows them to the operator, and asks which one, or invites the operator to type the literal route if none is right. The list is machine-extracted from the registry, so it is never wrong about what exists. The choice is the operator’s, because the choice is the part the machine cannot derive.
The function the feature skips was the one critical decision that had not been given this gate, so it got the same one. The grounding chat now ranks the reachable functions against the keywords and, instead of silently picking the top match or dying on a tie, surfaces them as a confirmation with the top-ranked candidate starred. The operator confirms enrichItem, picks a number, or types a name. That confirmed name is written into the structured handoff as the resolved target, and the pipeline uses it directly and never runs the keyword resolver. The keyword variance is now off the decision path. It no longer matters which stem set the model emitted, because the operator confirmed the function, and the function is what flows downstream into the conditional-skip operation, the implementation, and the behavioral oracle.
The measurement closes the loop. Five clean-baseline runs after the change: five successes, the same resolved target on all five. The model still emits a slightly different stem set run to run, which I did not fix and cannot. The variance no longer reaches anything that matters. The worst case is one extra confirmation question, never a silent wrong target, never a two-in-five coin-flip failure.
Three kinds of decision, and they do not get the same answer
The function identity is one decision the grounding chat faces. There are others, and the mistake I kept making was treating them as one problem with one fix. Surfacing the function as a confirmation is right. Surfacing every prose-shaped decision as a confirmation is not. Which move is correct depends on two things you can check mechanically from the call graph: does the operator’s answer change what the pipeline builds, and can the machine derive the answer itself.
Those two questions sort every decision into three buckets, and I only found all three by reading every prompt across the five-run measurements instead of accepting each one.

The first bucket is the function identity, and one decision past it, whether the flag should short-circuit the call or be threaded into it so the call still runs with the flag changing its behavior. Both of these change what gets built, and both are derivable. The resolver ranks the candidate functions by structural fit; the short-circuit-versus-thread question has a default the call graph can compute, because skipping exactly the named call and leaving its siblings running is the minimal-behavior-change option. So the move is to derive the framing and the default from structure and let the operator confirm the derived answer. The mode question used to be framed entirely by the model, and on identical prose it wobbled, re-scoping what the two options even meant and on one run labelling the same intent under the opposite option. Deriving the framing fixed it: five runs, identical, zero model-authored framings.
The second bucket is the over-ask the model invents that does not change anything. When measuring the mode fix, the model also surfaced a choice the prose never raised: when you skip enrichment, preserve or clear the already-cached enriched fields the previous run left on the record. It appeared in four runs out of five, and when it appeared its recommended answer flipped between contradictory outcomes. The instinct is to stabilise it. The right move is to check whether the answer changes anything first, and it did not. Both answers produced byte-identical operations. The pipeline emits no clearing operation in either case; the safe non-destructive behavior is what it already does. The operator’s pick was collected and then discarded. A confirmation whose answer you throw away is not a decision, it only looks like one. So the pipeline stopped asking, and the over-ask went from four-in-five to zero.
The third bucket is the one I had no answer for, and it is the one that names this post. The model also asked, non-deterministically, whether a downstream call, renderReport, which runs right after processItem in the same caller, should also be skipped when the flag is set. This one is real. The answer changes which downstream work runs and which work the tests assert. And it is not derivable. The call graph can prove renderReport runs and that it consumes the data processItem produces, but it cannot decide whether the operator wants it skipped. That is product intent the prose left open. There is no machine-derived default to put behind a confirmation, because there is no safe answer the structure points to. Skipping it changes the outcome; running it changes the outcome; the call graph is silent on which the operator meant.
So the pipeline does the thing its whole design is built around. It stops, names the specific downstream call it cannot make a decision about, and hands that decision back to the operator to settle in the ticket before anything is built. It is the decision the pipeline cannot make alone, so it does not try to. Across five clean-baseline runs the gate fired identically every time, the same call named every time, and the chat never silently chose. The cost is that an under-specified ticket stops early and asks for one more sentence, which is the correct cost.
Handing it back is not enough if you re-derive the answer
I thought that closed it, and then the measurement of the handed-back version taught the sharpest lesson in the whole arc.
The first version of hand-it-back asked the operator to add a sentence to the ticket: say what renderReport should do. The operator did, correctly, keep it running. And one run in five still built the wrong thing. Not the cascade this time. The resolver read the operator’s clarifying sentence, which now mentioned renderReport by name, and pinned renderReport as the function to act on, the exact function-identity wobble from the top of this post. The operator had answered correctly, and the pipeline laundered that answer back through the same model that guesses, which re-derived it wrong.
This is the lesson under all of it, one turn deeper than the function-identity fix.
Putting the operator in the loop is not the win on its own; what matters is keeping their answer out of the hands of the thing that hallucinates.
A decision you hand to the operator and then re-derive from their prose is not handed off at all; you have just added a human step in front of the same guess. The answer has to be captured as a structured choice the pipeline records and obeys, never as more prose for an LLM to re-read. That fix is now in place and proven for this flow. The cascade decision is captured in chat as a structured choice written into the handoff, the pipeline obeys it directly, and the operator’s clarifying sentence is no longer the thing the target is re-derived from, so the laundering is closed by construction. Both answers ran end to end on the real graph this session: keep it running proceeds with no extra operation, and also skip it builds a second guard on the parent call and went all the way to a passing build, the operator’s pick flowing through unchanged.

The third bucket is now answered in chat rather than by stopping. Both branches ran to a passing build this session: keep it running proceeds with no extra work, and also skip it builds a second guard on the parent call. The also-skip branch required one Coder call where everything else committed through deterministic operations, because what the skipped call returns is a contract decision the call graph does not carry.
What that build does not yet include is a dedicated bivalent unit test for the cascaded guard, because the call it suppresses sits in the same source file as the function that calls it and an intra-file call cannot be intercepted by the test framework, so that one gate is proven by the full suite and the Reviewer rather than in isolation. The intent-capture claim, that the operator’s decision reaches the build unchanged, holds regardless.
The rule
The version of the rule I started this arc with was that pushing structural decisions into deterministic, machine-extracted code removes the LLM from those decisions. That is necessary and it is not the whole of it. The complete rule has three moves and one constraint, and you pick the move by asking, from the call graph, whether the answer changes the build and whether the machine can derive it.
If the answer does not change the build, do not ask. Apply the safe default and move on. If the answer changes the build and the machine can derive it, derive the default, rank the options from structure, and let the operator confirm a computed answer. If the answer changes the build and the machine cannot derive it, do not offer a default-backed confirmation at all, because there is no honest default to offer. Stop and hand the decision to the operator. And the constraint that sits across all three: whatever the operator decides, capture it as structured data the pipeline obeys directly, never as prose you feed back through the model, or you reopen the exact hallucination you were closing.
A confirmation with a computed default is a cheap precision gate on top of cheap recall. A confirmation with a model-authored default passes a guess through a human who assumes it was computed, which is worse than no confirmation, because it adds the appearance of a check.
What this is not
This is one ticket family on one TypeScript codebase. Landing the implementation took ~150 runs across the week of 2026-06-03 to 2026-06-09, most of them development and debugging iteration. The determinism figures in this post are controlled clean-baseline batches within that larger effort: the same prose and the same answers, repeated five times, to isolate run-to-run variance. Five runs is a coarse instrument that shows whether the variance exists on a load-bearing path, not its precise rate: a 2-of-5 has too wide an interval to pin a rate on. Where a result was uncertain enough to matter the check was carried to fifteen runs, one round of which took a full day, and the durable fixes still remove the variance by construction rather than trusting any single batch’s measured percentage. It is not a benchmark, and the generalisation claim is narrower than the result might suggest.
It is also not an argument that the operator should be in the loop everywhere. The argument is narrower. Intent capture is the stage where operator knowledge belongs, because it is the stage that turns “what I want” into “which function,” and that translation depends on knowledge of the codebase the operator has and the prose does not carry. The downstream-cascade decision belongs there for the same reason: it is product intent, not structure. The other stages stay unattended.
It does not make the model unnecessary either. The model still does what it is good at: reading the prose, pulling the stems, proposing the ranking inputs. It stops being the thing that decides, and it stops being the thing the operator’s own answers are routed back through. The pipeline computes the decisions it can, asks the operator for the one it cannot, refuses to ask about the ones whose answers it would throw away, and keeps the answers it is given out of the model’s hands.
The pipeline runs inside Docker against a ~100k line TypeScript monorepo. Function names are anonymised. The measured numbers here are from the run archive of 2026-06-03 to 2026-06-09, one week inside a larger archive of ~950 runs, almost all of it the same handful of ticket families re-run to shake out non-determinism. Still R&D.